In “Obama and Probability” I neglected to link to three pertinent posts:
“Understanding the Monty Hall Problem“
“The Compleat Monty Hall Problem“
“‘Settled Science’ and the Monty Hall Problem“
Enjoy.
In “Obama and Probability” I neglected to link to three pertinent posts:
“Understanding the Monty Hall Problem“
“The Compleat Monty Hall Problem“
“‘Settled Science’ and the Monty Hall Problem“
Enjoy.
From The Epoch Times:
Former U.S. President Barack Obama said in a Feb. 14 podcast interview that aliens are real but that none are kept at the secretive Area 51 military base in the Nevada desert, later adding that he didn’t see any evidence indicating that extraterrestrials have contacted Earth during his presidency.
In the interview, when asked, “Are aliens real?” Obama replied, “They’re real, but I haven’t seen them—and they’re not being kept in [Area 51]. There’s no underground facility, unless there’s this enormous conspiracy and they hid it from the president of the United States.”Obama became the first leader of the United States to affirm the existence of extraterrestrial life when questioned by progressive podcaster Brian Tyler Cohen in a video posted on YouTube.After the interview went viral, Obama said on Instagram that he wanted to “clarify” his comments to Cohen, writing that he was “trying to stick with the spirit of the speed round” while speaking on the podcast.
“Statistically, the universe is so vast that the odds are good there’s life out there,” he wrote. “But the distances between solar systems are so great that the chances we’ve been visited by aliens is low, and I saw no evidence during my presidency that extraterrestrials have made contact with us. Really!”
Before I address Obama’s abysmal grasp of probability, I must note that he did not “affirm the existence of extraterrestrial life”. To have done that he would have offered compelling evidence of the existence of such life. He did not offer any evidence of the existence of such life, compelling or otherwise.
What he offered was an unsupported assertion: “the universe is so vast that the odds are good there’s life out there.” The assertion is unsupported because he didn’t discuss and doesn’t know (because no one does) the precise preconditions for life on Earth, or anywhere else, for that matter. It is safe to say that no one really knows the “odds” that life (of what kind?) is “out there”.
What about probability, which is implied in Obama’s invocation of “the odds”? Wikipedia offers a good starting point:
[T]here are two major competing categories of probability interpretations, whose adherents hold different views about the fundamental nature of probability:
- Objectivists assign numbers to describe some objective or physical state of affairs. The most popular version of objective probability is frequentist probability, which claims that the probability of a random event denotes the relative frequency of occurrence of an experiment’s outcome when the experiment is repeated indefinitely. This interpretation considers probability to be the relative frequency “in the long run” of outcomes….
- … The most popular version of subjective probability is Bayesian probability, which includes expert knowledge as well as experimental data to produce probabilities. The expert knowledge is represented by some (subjective) prior probability distribution…. By Aumann’s agreement theorem, Bayesian agents whose prior beliefs are similar will end up with similar posterior beliefs. However, sufficiently different priors can lead to different conclusions, regardless of how much information the agents share.
In other words, a probability is either (a) the observed frequency of an event of a given kind or (b) a guess.
There is no probability of alien life, in the frequentist interpretation of probability, because it isn’t the kind of phenomenon to which the frequentist interpretation applies.
Frequentist probability is about long-run averages, like the frequency of “heads” in a long series of coin flips. It says nothing about what might happen in the next coin flip. If the long-run average of “heads” is one-half, that tells you nothing about what will happen on the next flip. The next flip can’t be one-half of anything; it will be one of something: “heads” or “tails”.
That leaves subjective probability, which is just what it sounds like. You can make it up. Which is what Obama did. He simply asserted that “the odds” on alien life somewhere in the universe “are good” because the universe is “so vast”. He might as well have said something like this: The universe is so vast that there is someone out there who is identical to me, except that he opposes everything that I did as president.
And what does it mean to say that “the odds are good”, anyway? Nothing, actually, because you’re talking about something that might happen. A single event (e.g., the occurrence of alien life) doesn’t have a probability. It either exists or it doesn’t.
Subjective probability, as I said, is a guess. Weather forecasting is a blatant case in point. If a meteorologist says that the probability of rain in a given area is 30%, what he means is this: There is a 30% probability that some location in the specified area will receive at least 0.01 inches of measurable precipitation during the forecast period. That’s it — not how long it will rain, not how heavy it will be, and not how much of the area will get wet.
And how does the meteorologist arrive at 30%? Forecasts rely on many model simulations. If 30 out of 100 model runs show rain, that yields a 30% chance of rain. It’s guesswork all the way down because models are nothing more than collections of guesses about the relevant variables, their values, and their relationships to each other (For more about models and modeling, see this, this, this, this, this, this, this, and this.)
Obama’s statement was in keeping with his political rhetoric: pure bull***t.
I’ve been occupied by a lot of things since my previous post more than three months ago. One of the things is a treatise on liberty in America, which will appear in due course, that is, when I’m satisfied with it.
In the meantime, you might enjoy an excursion into my writings about the frailties of science and philosophy. The following links are in chronological order (some links within may be broken):
“Science” vs. Science: The Case of Evolution, Race, and Intelligence
Analytical and Scientific Arrogance
The Enlightenment’s Fatal Flaw
Intellectuals and Authoritarianism
Coronavirus Update: The Control Freaks in the U.S. (and Elsewhere) Blew It
Thomas Sowell’s “Intellectuals and Society”
Philosophical Musings, Part V: Desiderata as Beliefs
Is Scientific Skepticism Irrational?
Keynesian Multiplier: Fiction vs. Fact
Climate Change: A Bibliography
The Problem of Attributing Causality
The Search for Truth: From Science to Conspiracy Theories
If anything on that list whets your appetite for more in the same vein, go here. But be aware that the links that lead to my old blog, Liberty Corner, no longer work. You can find the same posts at Politics & Prosperity by using the search box at the top of the sidebar and searching on the title of the post (enclosed in quotation marks).
Any set of observations has an infinite number of explanations.
— William M. Briggs (Science Is Not the Answer)
The main difference between mathematical formulae and the real world is that the formulae usually reduce open-ended reality to closed-form hypotheses about reality. By closed form, I mean that the hypotheses include only a limited number of factors that determine what is observed (not to mention the inevitable errors in the estimation of the values and weights of those factors).
“Climate change” is exhibit A when it comes to the failure of mathematical formulae to replicate reality. In addition to the many well-researched articles (e.g., here) that challenge the general “scientific” view that CO2 drives atmospheric temperatures, there is Alan Longhurst‘s Doubt and Certainty in Climate Science. Longhurst adduces dozens of factors that influence atmospheric (and oceanic) temperatures — factors that are ignored or insufficiently accounted for in global climate models (GCMs) — while also documenting the wide range of uncertainty about the values and weights of such factors. A more accessible and powerful indictment of “climate change” is the report by John Christy et al., John Christy et al., “A Critical Review of Impacts of Greenhouse Gas Emissions on the U.S. Climate“.
As in too many other cases, GCMs are built upon foundations of sand — their developers’ biases. Examples abound of models equally devoid of reality because they reflect what their builders wish to be true.
One model that is on a par with GCMs in its destructive effects is the Keynsesian multiplier, which for more than 80 years has been used to justify government spending, a vastly destructive undertaking. (For more about biases — known more charitably as assumptions — see Arnold Kling’s post, “The God’s-Eye View of the Economy“.)
Also in the realm of economics, there is the failure of complex macroeconomic models to predict accurately quarter-to-quarter changes in GDP. I last addressed the subject eight years ago. Here’s key graph from that post:

“Fair” refers to Professor Ray C. Fair of Princeton University, the creator of the model in question. The model isn’t fair (as in fair to middling), it’s a dismal failure. Most of the errors are huge.
If the Fair model seems bad, consider the forecasts of changes in GDP that are published by the Federal Reserve Bank of Atlanta at GDPNow. The forecasts are expressed as changes in the annual rate of real (inflation-adjusted) growth in GDP. The website includes a misleading graph of the increasing accuracy of the forecasts. It is misleading because the forecasts are compared to the initial estimates of quarterly GDP changes issued by the Bureau of Economic Analysis (BEA). When the estimates are compared with BEA’s final estimates of quarterly GDP, this is the result:
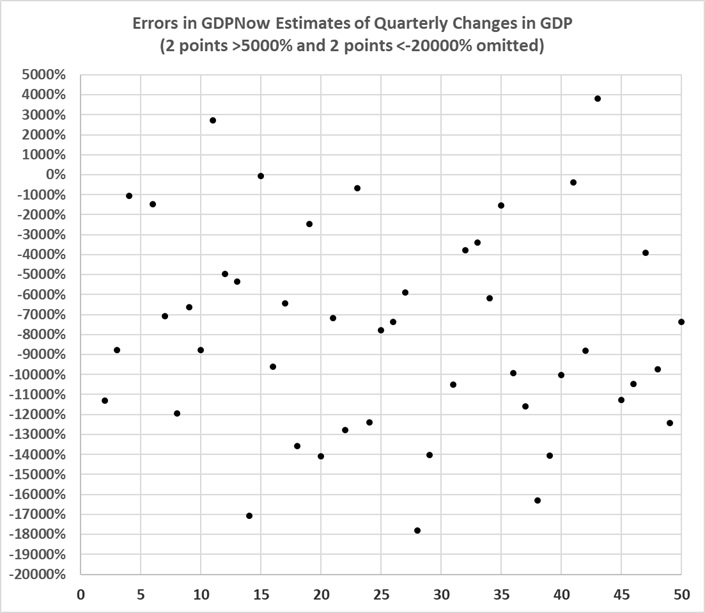
Need I say more?
Just one more thought about economics before I shift to a seemingly sacrosanct model: Einstein’s general theory of relativity. The additional thought is this: GDP is defined by simple equations, the simplest of which is GDP = C + I + G, where C is consumption expenditures, I is investment expenditures, and G is government expenditures. The equation implies that GDP rises if G rises. But that isn’t the case, as shown here.
Economics is a soft target. General relativity is a relatively (pun) hard one. But it’s not impregnable. To begin where we ought to begin, “theory” (in the physical sciences) refers to a hypothesis that has been “confirmed” by evidence (experiments, observations) and remains valid (e.g., consistently accurate in predicting the behavior of objects within its scope).
There’s a subtle catch, however. As William Briggs observes here,
Classical hypothesis testing is founded on the fallacy of the false dichotomy. The false dichotomy says of two hypotheses that if one hypothesis is false, the other must be true.
In the case of general relativity, which is really an explanation of gravity, it became obvious that Newton’s “law” of gravitation is inadequate on a large scale (e.g., it couldn’t explain the precession of Mercury’s orbit). It is considered “correct enough” on a small scale (e.g., Earth), but “incomplete”. Which is to say that it is incorrect.
General relativity solved the precession problem, among others. But is it correct, that is, complete? Apparently not. As scientists learn more and more about the universe, lacunae abound in the general theory:
The current understanding of gravity is based on Albert Einstein‘s general theory of relativity, which incorporates his theory of special relativity and deeply modifies the understanding of concepts like time and space. Although general relativity is highly regarded for its elegance and accuracy, it has limitations: the gravitational singularities inside black holes, the ad hoc postulation of dark matter, as well as dark energy and its relation to the cosmological constant are among the current unsolved mysteries regarding gravity,[3] all of which signal the collapse of the general theory of relativity at different scales and highlight the need for a gravitational theory that goes into the quantum realm. At distances close to the Planck length, like those near the center of a black hole, quantum fluctuations of spacetime are expected to play an important role.[4] Finally, the discrepancies between the predicted value for the vacuum energy and the observed values (which, depending on considerations, can be of 60 or 120 orders of magnitude)[5][6] highlight the necessity for a quantum theory of gravity.
Imagine the errors in all of the equations that are used (explicitly or implicitly) in the making of things that human beings use. What saves humanity from utter chaos — in the physical realm — is the practice of “over-building” — allowing for abnormal conditions and unknown factors in the construction of machinery, vehicles, buildings, aircraft, spacecraft, etc. Even then, the practice is often ignored or inadequate in particular situations (e.g., rocket-launch failures, bridge collapses, aircraft accidents).
The usual response to the failure of physical systems is that they are the result of “random events”. In fact, when they occur in spite of “over-building” they are the result of the inadequacy of equations to capture reality.
This brings me to so-called conspiracy theories (hypotheses, really). Some of them are patently ludicrous. Others are plausible. Most famously, perhaps, are hypotheses about who really killed JFK (or had him killed), and how he was killed. Those who scoff at such hypotheses usually do so because they don’t want them to be correct, and wish to hew to the official line. Hypotheses about the killing of JFK are plausible because of uncertainty about the “facts” that support the official view of events: Lee Harvey Oswald was the lone gunman and he acted alone.
In the case of the assassination of JFK, the following questions reflect some of the uncertainty about several (but far from all) of the official “facts”:
And so on.
The real world is full of uncertainty. But few human beings seem to be comfortable with it. Thus, crap science, science on a pedestal (of sand), and conspiracy theories.
What we wish for ourselves — decisions that have certain outcomes — isn’t aligned with the way the world works. But we keep trying, despite the odds. What else can we do?
It is my view that genetic fitness for survival has become almost irrelevant in places like the North America, Europe, and Japan. There is a supportable hypothesis that humans in those cosseted realms are, on average, becoming less intelligent. The less-intelligent portions of the populace are breeding faster than the more-intelligent portions.
The rise of technology and the “social safety net” (state-enforced pseudo-empathy) have enabled the survival and reproduction of traits that would have dwindled in times past. Evolution — in the absence of challenges that ensure survival of the fittest — seems to have resulted in devolution. The evidence is all around us.
Epistemology: The branch of philosophy that examines the nature of knowledge, its presuppositions and foundations, and its extent and validity.
Experience (observation) and logic yield hypotheses about discrete phenomena and the workings of natural and constructed entities. Hypotheses are provisional because of the possibility of error and the fact that universal generalization is impossible.
Hypotheses about how things work are nevertheless useful — nay, indispensable — to life and its improvement. But nothing is certain because hypotheses are necessarily limited in their application. Why? Because they are abstractions that cannot account for human error and the variability of physical phenomena.
Experience shows, for example, that a cake recipe (which is a hypothesis about how to bake a cake) cannot guarantee the production of an edible cake of certain dimensions. In addition to wide variations in the ability of cooks (especially amateurs), there are wide variations in the quality and freshness of ingredients, the adequacy of tools (e.g., sifters and whisks), and the precision with which ovens can maintain specified temperatures.
Similar considerations — but far more serious ones — apply to “recipes” for constructing buildings, highways, bridges, aircraft, spacecraft, etc. The “recipe” for estimating the effect of human activity (CO2 emissions) on climate is deeply flawed by human bias, measurement error, and failure to adequately account for relevant “ingredients” (some of which remain unknown). “The science” is never settled; for example, an apparent error in Einstein’s general theory of relativity is just one of the many problems that still daunt scientists.
Error (failure) is an epistemological fact of life. It may be possible to predict the fact of error (e.g., a novice bowler will not bowl a 200 game) but the magnitude of error can be known only after the fact. That is why critical systems (e.g., bridges and aircraft) are usually built to withstand extreme conditions. But they still sometimes fail.
Related post: Words Fail Us
An esteemed correspondent sent me a link to “Arguments for God Tier-List“, a post at Bentham’s Newsletter on Substack. The author, who goes by Bentham’s Bulldog, begins his post with this explanation:
Tier lists rank arguments for God on a scale from F to S, where F is the worst, S is the best, and the rest follow a traditional letter grade—A better than B, B better than C, and so on.
He notes that his “views on which arguments for God are good diverges sharply from the standard views.” That’s for sure. His favorite argument, the anthropic argument, to which he assigns a grade of S (followed by three heart emojis), isn’t an argument for God. I am hard-pressed to say what it is an argument for, if anything.
Here’s Bulldog’s summary of the anthropic argument:
Where is God? He is nowhere to be found in that gibberish, nor in Bulldog’s two long attempts to explain the anthropic argument (here and here), except in name. His existence is merely assumed, there is no attempt to prove it.
This brings me to what I consider to be the most compelling argument for God’s existence. It is the cosmological argument discussed by Bulldog here:
That’s a good argument for God’s existence, though I have a shorter version:
“What is the math question to which string theory is the only answer?” That question appears in an article about string theory which an esteemed correspondent sent to me.
You might wonder what string theory is. The article describes it thus:
String theory posits that the most basic building blocks of nature are not particles, but, rather, one-dimensional vibrating strings that move at different frequencies in determining the type of particle that emerges — akin to how vibrations of string instruments produce an array of musical notes.
My son found an entertaining video that puts string theory in perspective>
That is about the extent of my knowledge of string theory. I am, however, curious about the idea that a string (which is a kind of line) can be one-dimensional. A point is one-dimensional; a string (the abstract kind, not the one your kitten plays with) is two-dimensional. Ah, the mysteries of the universe.
In any event, I have no idea what kind of math question might produce “string theory” as the one and only answer. But I do know that it is possible in mathematics to get the same answer by using many different equations.
Consider 4, which is a nice small, round number. There are infinitely many ways to get 4 as the answer to an equation by using arithmetic, algebra, differential calculus, integral calculus, and so on. Here are three of the many possible ways of writing an algebraic equation, where y stands for desired answer (4):
In each case, 4 is the desired answer, a and b are parameters with known values, and x is the number that produces 4 given the values of a and b . Given a = 1 , b = 2 , and c = 3 , x takes the following values in each equation:
There can be many more — and more complex — algebraic equations that the four in my example. There can be many more parameters than a , b , and c in each of the equations. Every parameter in every equation can take an infinite number of values. And, as noted above, the mathematical operations that produce the desired result might be expressed by many types of equation — from arithmetic and algebra to calculus and beyond.
In other words, it might be possible to produce an equation to which “string theory” is the answer. But it seems that it might be possible to produce an infinitude of equations to which “string theory” is the answer. Where does that get us?
Is there a cosmologist in the crowd?
I was reminded of the problem of attributing causality by “Did Major League Baseball Really Have a ‘Steroid Era‘”, which throws cold water on the belief that the barrage of home runs for about a decade from the mid-1990s to the mid-2000s was mainly attributable to the use of performance-enhancing drugs (PEDs). I also threw cold water on that hypothesis several years ago in “Steroids in Baseball: A Counterproductive Side show or an Offensive Boom?“.
The attribution of changes in a particular statistic (e.g., home runs) to one or a few causal factors is scientism (see number 2). There is also a tendency to allow preconceptions to dictate the selection of causal factors (see “Climate Change” and “Can America Be Saved?“).
Baseball, like life and many of the phenomena addressed by science, is too complex for simple explanatory models. I was reminded of this when I read Alan Longhurst’s Doubt and Certainty in Climate Science. It is a masterful review of what is known and unknown about the myriad phenomena that influence climate. Uncertainties and lacunae abound, as Longhurst shows in his examination of the findings related to dozens of climate-influencing phenomena. Longhurst’s analysis of the findings (and lack thereof) makes a mockery of the pseudo-precision of temperature forecasts made by global climate models — models that can’t even replicate the past accurately (see “Climate Change” and “Climate Change: A Bibliography“).
In that regard, I must emphasize that modeling is not science. It is, rather, reductionism: the practice of oversimplifying a complex idea or issue (see “The Enlightenment’s Fatal Flaw“).
Scientism and reductionism are nowhere more rampant (and destructive) than in governmental actions authorized by legislation and regulation. A “problem” is perceived, usually as the result of a massive media campaign triggered by an incident, “scientific finding”, or interest-group pressure. The result is a clamor for “somebody” to do “something” about the “problem”. The response that has become habitual since the onset of the Progressive Era is to invoke the power of the central government. (In almost all cases, the power invoked can be found in the Constitution only by contorting it beyond recognition by its Framers.)
Thus are born, nourished, and defended various powers and “rights” that have unforeseen (or willfully ignored) consequences for the general welfare of Americans. Why? Because executives, legislators, regulators, and judges are ignorant of (or don’t care about) the fact the most “problems” have myriad causes — causes that aren’t (and usually can’t be) addressed by executive orders, laws, regulations, or judicial decrees. The usual suspects are also ignorant of (or don’t care about) the ramifications of efforts to fix “problems” through the aforementioned means.
I am reminded of the scam that is management consulting by an article at Econ Journal Watch, “McKinsey’s Diversity Matters/Delivers/Wins Results Revisited“. (McKinsey is McKinsey & Company, a prestigious consulting firm founded in 1926.) I have read the article, and it firmly support the claims made in its abstract:
In a series of very influential studies, McKinsey (2015; 2018; 2020; 2023) reports finding statistically significant positive relations between the industry-adjusted earnings before interest and taxes margins of global McKinsey-chosen sets of large public firms and the racial/ethnic diversity of their executives. However, when we revisit McKinsey’s tests using data for firms in the publicly observable S&P 500® as of 12/31/2019, we do not find statistically significant relations between McKinsey’s inverse normalized Herfindahl-Hirschman measures of executive racial/ethnic diversity at mid-2020 and either industry-adjusted earnings before interest and taxes margin or industry-adjusted sales growth, gross margin, return on assets, return on equity, and total shareholder return over the prior five years 2015–2019. Combined with the erroneous reverse-causality nature of McKinsey’s tests, our inability to quasi-replicate their results suggests that despite the imprimatur given to McKinsey’s studies, they should not be relied on to support the view that US publicly traded firms can expect to deliver improved financial performance if they increase the racial/ethnic diversity of their executives [emphasis added].
McKinsey’s studies about the supposed benefits of diversity were produced for corporate clients. Specifically, they would have been produced for senior executives of corporations, most likely at the direction of or with the close involvement of vice presidents for human resources (i.e., personnel). I would be willing to place a wager that McKinsey’s results were just what the clients wanted, corporate culture being what it had become by the time McKinsey was called in to ratify diversity.
In that respect, McKinsey is far from alone. I worked at a not-for-profit consulting firm in the Washington DC area for 30 years. We looked down on the for-profit firms of which McKinsey is one of dozens (if not hundreds). They were known crudely but with some justice as Beltway Bandits, and more accurately as Highway Helpers. Their job (unacknowledged but obvious to anyone who read their output) was to deliver findings that served their clients’ interests. Those interests, in most cases were the justification of systems and processes being considered for procurement by government agencies. When the clients were government agencies, the findings justified whatever systems and processes were favored by those agencies.
But, to be candid, the same kind of relationship often existed between non-for-profits (like the one I worked for) and their government clients. We knew what the clients wanted to hear, and we often found ways to deliver results that made them happy. The first major project to which I was assigned went that way, and I observed (and sometimes participated in) projects that were similarly biased. One time, when I delivered to an admiral a candid — and negative — appraisal of his pet project, I was declared persona non grata in his branch of the Navy’s DC establishment.
The main exception to this kind of behavior occurred in the field, where my former employer’s analysts worked with Navy and Marine Corps operators to evaluate the effectiveness of systems and tactics — sometimes in actual combat situations. There, where lives were at stake (or could be at stake), operators usually wanted the unvarnished facts. And that’s what they got from the analysts in the field. But those analysts comprised (and still comprise) a tiny fraction of the thousands of analysts who worked for Beltway Bandits/Highway Helpers and their not-for-profit brethren.
Consulting to U.S.-government agencies on a grand scale grew out of the perceived successes in World War II of civilian analysts who were embedded in military organizations. To the extent that the civilian analysts were actually helpful,* it was because they focused on specific operations, such as methods of searching for enemy submarines. In such cases, the government client can benefit from an outside look at the effectiveness of the operations, the identification of failure points, and suggestions for changes in weapons and tactics that are informed by first-hand observation of military operations.
Beyond that, however, outsiders are of little help, and may be a hindrance, as in the case cited in a Politico article that I address here. (Which is far from unique.) Outsiders can’t really grasp the dynamics and unwritten rules of organizational cultures that embed decades of learning and adaptation.
The consulting game is now (and has been for decades) an invasive species. It is a perverse outgrowth of operations research as it was developed in World War II. Too much of a “good thing” is a bad thing — as I saw for myself many years ago.
__________
* The success of the U.S. Navy’s antisubmarine warfare (ASW) operations had been for decades ascribed to the pioneering civilian organization known as the Antisubmarine Warfare Operations Research Group (ASWORG), the predecessor of the organization for which I worked. However, with the publication of The Ultra Secret in 1974 (and subsequent revelations), it became known that codebreaking may have contributed greatly to the success of various operations against enemy forces, including ASW.
See also “Modeling Is Not Science“, “Analytical and Scientific Arrogance“, and “Management Science” in “The Balderdash Chronicles“.
Bill Vallicella (Maverick Philosopher) asserts that
No one has successfully answered Zeno’s Paradoxes of Motion. (No, kiddies, Wesley Salmon did not successfully rebut them; the ‘calculus solution’ is not a definitive (philosophically dispositive) solution.)
The link in the quoted passage leads to a post from 2009 in which BV addresses Zeno’s Regressive Dichotomy:
The Regressive Dichotomy is one of Zeno’s paradoxes of motion. How can I get from point A, where I am, to point B, where I want to be? It seems I can’t get started.
A_______1/8_______1/4_______________1/2_________________________________ B
To get from A to B, I must go halfway. But to travel halfway, I must first traverse half of the halfway distance, and thus 1/4 of the total distance. But to do this I must move 1/8 of the total distance. And so on. The sequence of runs I must complete in order to reach my goal has the form of an infinite regress with no first term:
. . . 1/16, 1/8, 1/4, 1/2, 1.
Since there is no first term, I can’t get started.
Zeno’s paradox rests on the assumption that a first step is an infinitesimal fraction of the distance to be traversed, a fraction that can never be resolved mathematically. But that is an obviously false and arbitrary assumption.
Zeno, had he been less provocative (though mundane), would have observed that first step in going from A to B is a random distance that depends on the stride of the traveler; it has nothing to do with the distance to be traversed.
Thus, the distance from point A to point B can be traversed in x strides, where
x = d/l
and
d = distance from A to B
l = average length of stride.
That’s all f-f-folks.
See also “Achilles and the Tortoise Revisited“.
ADDENDUM BELOW
I observed, in November 2020, that there is no connection between CO2 emissions and the amount of CO2 in the atmosphere. This suggests that emissions have little or no effect on the concentration of CO2. A recent post at WUWT notes that emissions hit a record high in 2021. What the post doesn’t address is the relationship between emissions and the concentration of CO2 in the atmosphere.
See for yourself. Here’s the WUWT graph of emissions from energy combustion and industrial processes:
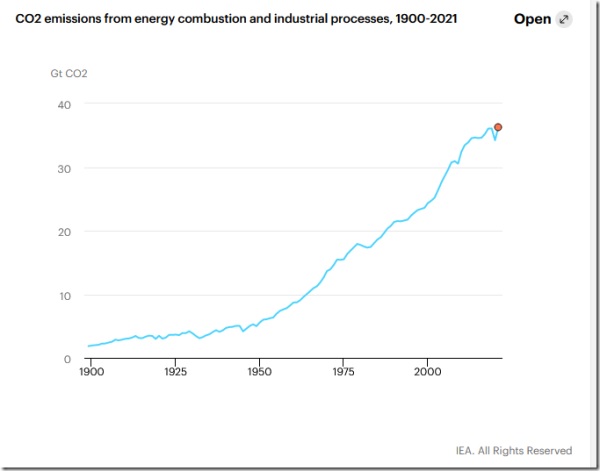
Here’s the record of atmospheric CO2:

It’s obvious that CO2 has been rising monotonically, with regular seasonal variations, while emissions have been rising irregularly — even declining and holding steady at times. This relationship (or lack thereof) supports the thesis that the rise in atmospheric CO2 is the result of warming, not its cause.
ADDENDUM (04/09/22):
Dr. Roy Spencer, in a post at his eponymous blog, writes:
[T]he greatest correlations are found with global (or tropical) surface temperature changes and estimated yearly anthropogenic emissions. Curiously, reversing the direction of causation between surface temperature and CO2 (yearly changes in SST [dSST/dt] being caused by increasing CO2) yields a very low correlation.
That is to say, temperature changes seem to drive CO2 levels, not the other way around (which is the conventional view).
Sources for CO2 levels:
https://gml.noaa.gov/ccgg/trends/gl_data.html
https://gml.noaa.gov/ccgg/trends/data.html
Related reading: Clyde Spencer, “Anthropogenic CO2 and the Expected Results from Eliminating It” [zero, zilch, zip, nada], Watts Up With That?, March 22, 2022
Change upsets settled relationships. If change is mutually agreed, the parties to it are more likely than not to have anticipated and planned for its effects. If change is imposed, the imposing parties will have only a dim view of its effects and the parties imposed upon will have only scant knowledge of its likely effects; in neither case will the effects of change be well anticipated or planned for.
Opposition to change is a wise first-order response.
A correspondent sent me a link to a video about Greenland ice core records. He called the video an eye opener, which is rather surprising to me because the man is a trained scientist and an experienced analyst of quantitative data. The video wasn’t at all an eye-opener for me. Here is my reply to the correspondent:
I began to look seriously at global warming ~2005, and used to write extensively about it. The info provided in the video is consistent with other observations, including icc-core measurements taken at Vostok, Antarctica. Here’s a related post, which includes the Vostok readings and much more: http://libertycorner.blogspot.com/2007/08/more-climate-stuff.html. Some of the other evidence that I have accrued is summarized here: https://politicsandprosperity.com/climate-change/.
Findings like those presented in the video seem to have no effect on the politics of “climate change”. It is a chimera, concocted by “scientists” who manipulate complex models (which have almost no predictive power) and, on the basis of those models, constantly adjust historical temperature readings to comport with what should have happened according to the models. (Thus “proving” the correctness of the models.) This kind of manipulation is widely known and well documented, as is the predictive failure of the models. But there is a “climate change” industry — a government-academic-media complex if you will — that has a life of its own, and it has transformed what should be a scientific issue into a secular religion. Due in no small part to the leftist leanings of public-school and university educators, tens of millions of American children and young adults have been brainwashed into believing that Earth is headed for a fiery denouement if “evil” things like fossil fuels aren’t banned. Being impressionable — not to mention scientifically and economically illiterate — they don’t question the pseudo-science that underlies “climate change” or the consider the economic consequences of drastic anti-warming measures, which would yield (at best) a lowering of Earth’s average temperature by ~0.1 degree by 2100 in exchange for a return to the horse-and-buggy age.
Here’s what I left unsaid:
The only possible way to defeat the “climate change” industry is to elect politicians who firmly reject its “intellectual” foundations and its draconian prescriptions. There was one such politician who managed to claw his way to the top in the U.S., but he was turned out of office, due in large part to the efforts a powerful cabal (https://time.com/5936036/secret-2020-election-campaign/) which is heavily invested in an all-powerful central government that can shape the U.S. to its liking. It didn’t help that the politician was rude and crude, which turned off fastidious voters (like you) who didn’t think about or care about the consequences of a Democrat return to power.
End of rant.
In “The ‘Marketplace’ of Ideas” I observe that
[u]nlike true markets, where competition usually eliminates sellers whose products and services are found wanting, the competition of ideas often leads to the broad acceptance of superstitions, crackpot notions, and plausible but mistaken theories. These often find their way into government policy, where they are imposed on citizens and taxpayers for the psychic benefit of politicians and bureaucrats and the monetary benefit of their cronies.
The “marketplace” of ideas is replete with vendors who are crackpots, charlatans, and petty tyrants. They run rampant in the media, academia, and government.
Caveat emptor.
Think [about] Nazism, Communism, various religions, Rastafarianism, and other -isms without number. Millions of people actually believe these things, often without reservation. The marketplace of ideas at best works only, ah, imperfectly, you might say. You also might say it’s always just a half-step away from disaster.
Maybe, but they’re not game changers. It’s more likely that (a) the most vulnerable citizens were picked off in the first three waves of the pandemic, and (b) herd immunity has been mainly responsible for the recent declines in the rates of new cases and deaths.
In graph below I have plotted 7-day moving averages of the daily numbers of new COVID-19 cases and deaths. (The plot of deaths is moved to the right by 24 days because the highest correlation between cases and deaths occurs with a 24-day lag from cases to deaths.) Although the case rate began to decline in mid-January 2021, the death rate held steady through mid-March, and then began to drop only after about 10 percent of the populace had been fully vaccinated. It seems unlikely that 10 percent would have been a game-changer.
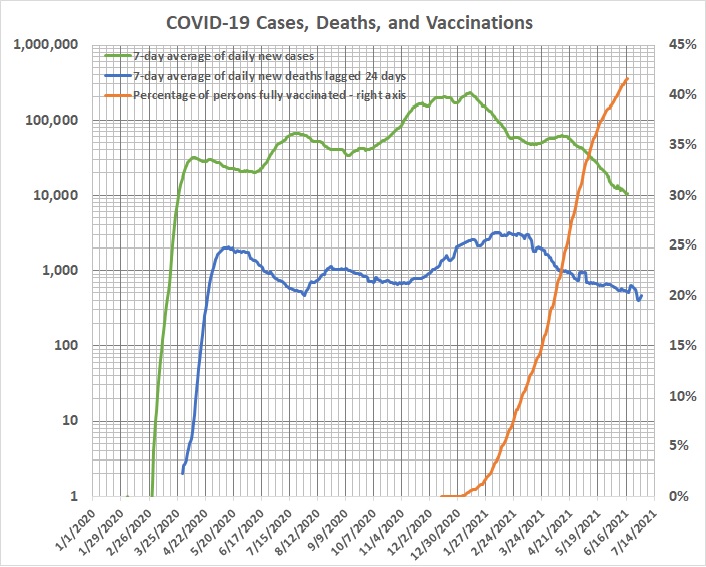
In any event, the COVID pandemic is not nearly as lethal as the Spanish flu, which the hardier Americans of more than a century ago managed to survive without the benefit of vaccines:
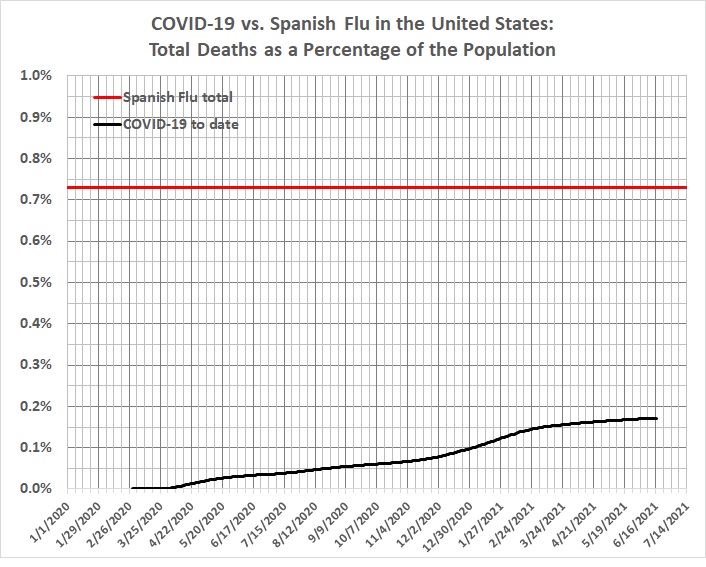
With deaths at less than 0.2 percent of the population, it is unsurprising that most Americans don’t know (or know of) anyone who died from COVID. How is it that such an inconsequential disease brought a country to its knees and enabled petty tyrants to deprive Americans of their liberty?
The answer: Decade upon decade of indoctrination by the media and public-school “educators” in the belief that the nanny state knows best.
Related reading: “PA”, “‘No Substantial Outbreaks’ From Large Events Pilot Scheme, Says Report“, The Epoch Times, June 25, 2021
I am using “wokesters” as a convenient handle for persons who subscribe to a range of closely related movements, which include but are not limited to wokeness, racial justice, equity, gender equality, transgenderism, social justice, cancel culture, environmental justice, and climate-change activism. It is fair to say that the following views, which might be associated with one or another of the movements, are held widely by members of all the movements (despite the truths noted parenthetically):
Race is a social construct. (Despite strong scientific evidence to the contrary.)
Racism is a foundational and systemic aspect of American history. (Which is a convenient excuse for much of what follows.)
Racism explains every bad thing that has befallen people of color in America. (Ditto.)
America’s history must be repudiated by eradicating all vestiges of it that glorify straight white males of European descent. (Because wokesters are intolerant of brilliance and success of it comes from straight white males of European descent.)
The central government (when it is run by wokesters and their political pawns) should be the sole arbiter of human relations. (Replacing smaller units of government, voluntary contractual arrangements, families, churches, clubs, and other elements of civil society through which essential services are provided, economic wants are satisfied efficiently, and civilizing norms are inculcated and enforced), except for those institutions that are dominated by wokesters or their proteges, of course.)
[You name it] is a human right. (Which — unlike true rights, which all can enjoy without cost to others — must be provided at cost to others.)
Economics is a zero-sum game; the rich get rich at the expense of the poor. (Though the economic history of the United States — and the Western world — says otherwise. The rich get rich — often rising from poverty and middling circumstances — by dint of effort risk-taking, and in the process produce things of value for others while also enabling them to advance economically.)
Profit is a dirty word. (But I — the elite lefty who makes seven figures a year, thank you, deserve every penny of my hard-earned income.)
Sex gender is assigned arbitrarily at birth. (Ludicrous).
Men can bear children. (Ditto.)
Women can have penises. (Ditto.)
Gender dysphoria in some children proves the preceding poiXXXX
Children can have two mommies, two daddies, or any combination of parents in any number and any gender. And, no, they won’t grow up anti-social for lack of traditional father (male) and mother (female) parents. (Just ask blacks who are unemployed for lack of education and serving prison time after having been raised without bread-winning fathers.)
Blacks, on average, are at the bottom of income and wealth distributions and at the top of the incarceration distribution — despite affirmative action, subsidized housing, welfare payments, etc. — because of racism. (Not because blacks, on average, are at the bottom of the intelligence distribution and have in many black communities adopted and enforced a culture the promotes violence and denigrates education?)
Black lives matter. (More than other lives? Despite the facts adduced above?)
Police are racist Nazis and ought to be de-funded. (So that law abiding blacks and other Americans can become easier targets for rape, murder, and theft.)
Grades, advanced placement courses, aptitude tests, and intelligence tests are racist devices. (Which happen to enable the best and brightest — regardless of race, sex, or socioeconomic class — to lead the country forward scientifically and economically, to the benefit of all.)
The warming of the planet by a couple of degrees in the past half-century (for reasons that aren’t well understood but which are attributed by latter-day Puritans to human activity) is a sign of things to come: Earth will warm to the point that it becomes almost uninhabitable. (Which is a case of undue extrapolation from demonstrably erroneous models and a failure to credit the ability of capitalism — gasp! — to adapt successfully to truly significant climatic changes.)
Science is real. (Though we don’t know what science is, and believe things that are labeled scientific if we agree with them. We don’t understand, or care, that science is a process that sometimes yields useful knowledge, or that the “knowledge” is always provisional, always in doubt, and sometimes wrong. We support the movement of recent decades to label some things as scientific that are really driven by a puritanical, anti-humanistic agenda, and which don’t hold up against rigorous, scientific examination, such as the debunked “science” of “climate change”; the essential equality of the races and sexes, despite their scientifically demonstrable differences; and the belief that a man can become a woman, and vice versa.)
Illegal immigrants migrants are just seeking a better life and should be allowed free entry into the United States. (Because borders are arbitrary — except when it comes to my property — and it doesn’t matter if the unfettered enty ro illegal immigrants burdens tax-paying Americans and takes jobs from working-class Americans.)
The United States spends too much on national defense because (a) borders are arbitrary (except when they delineate my property), (b) there’s no real threat to this country (except for cyberattacks and terrorism sponsored by other states, and growing Chinese and Russian aggression that imperils the economic interests of Americans), (c) America is the aggressor (except in World War I, World War II, the Korean War, the Vietnam War, Gulf War I, the terrorist attacks on 9/11, and in the future if America significantly reduces its defense forces), and (d) peace is preferable to war (except that it is preparedness for war that ensures peace, either through deterrence or victory).
What wokesters want is to see that these views, and many others of their ilk, are enforced by the central government. To that end, steps will be taken to ensure that the Democrat Party is permanently in control of the central government and is able to control most State governments. Accordingly, voting laws will be “reformed” to enable everyone, regardless of citizenship status or other qualification (perhaps excepting age, or perhaps not) to receive a mail-in ballot that will be harvested and cast for Democrat candidates; the District of Columbia and Puerto Rico (with their iron-clad Democrat super-majorities) will be added to the Union; the filibuster will be abolished; the Supreme Court and lower courts will be expanded and new seats will be filled by Democrat nominees; and on, and on.
Why do wokesters want what they want? Here’s my take:
What will wokesters (and all of us) get?
At best, what they will get is a European Union on steroids, a Kafka-esque existence in a world run by bureaucratic whims from which entrepreneurial initiative and deeply rooted, socially binding cultures have been erased.
Somewhere between best and worst, they will get an impoverished, violent, drug-addled dystopia which is effectively a police state run for the benefit of cosseted political-media-corprate-academic elites.
At worst (as if it could get worse), what they will get is life under the hob-nailed boots of Russia and China:; for example:
Russians are building a military focused on killing people and breaking things. We’re apparently building a military focused on being capable of explaining microaggressions and critical race theory to Afghan Tribesmen.
A country whose political leaders oppose the execution of murderers, support riots and looting by BLM, will not back Israel in it’s life-or-death struggle with Islamic terrorists, and use the military to advance “wokeism” isn’t a country that you can count on to face down Russia and China.
Wokesters are nothing but useful idiots to the Russians and Chinese. And if wokesterst succeed in weakening the U.S. to the point that it becomes a Sino-Soviet vassal, they will be among the first to learn what life under an all-powerful central government is really like. Though, useful idiots that they are, they won’t survive long enough to savor the biter fruits of their labors.
I am revisiting David Stove‘s Popper and Beyond: Four Modern Irrationalists. There is something “off” about it, which is captured in a review at Amazon:
Here is Stove’s argument, reduced to its essence:
Stove assumes that which he seeks to prove. His reasoning is therefore circular. His book is a waste of ink, paper, and pixels (depending on the format in which it is published).
Stove, nevertheless (unwittingly) poses a question that demands an answer: If scientific knowledge is provisional (as it always is), is it possible to say that scientific knowledge has progressed; that is, more is known about the universe and its contents than was known in the past?
The provisional answer is “yes”. Human knowledge of the universe progresses, in general, but it is never certain knowledge and some of it is false knowledge (error). Witness the not-so-settled science of cosmology, which has been in flux for eons.
There is broad but not universal agreement that the universe (or at least the part of the universe which is observable to human beings) originated in a Big Bang. Expansion followed. But the rate of expansion of the universe and the cause(s) of that expansion remain beyond the ken of science. The knowledge that the universe is expanding — and expanding at an ever-increasing rate — is an advance on prior knowledge (or belief), which held that the universe is contracting or that it is neither contracting nor expanding. But the knowledge of an accelerating expansion must be provisional because new observations may yield a different description of the universe.
That example brings us to the essential dichotomy of science: observation vs. explanation. What is observed is observed with varying degrees of certainty. The variations depend on the limitations of our instruments, sensory organs, and brains (which may be conditioned to misperceive some phenomena). Where things often go awry is in explaining that which is perceived, especially if the perception is wrong.
A classic case of misperception is the once-dominant belief that the Sun circles Earth. It’s easy to see how that misperception arose. But having arisen, it led to erroneous explanations. One erroneous explanation was that the Sun is embedded in a “sky dome” that surrounds Earth at some distance and rotates around it.
A current case of misperception is the deliberately inculcated belief that the general rise in observed temperatures on Earth from the late 1970s to late 1990s is due almost entirely to an increase in the atmospheric concentration of CO2 caused by human activity. The dominance of that theory — which objective observers know to be incomplete and unsubstantiated — may well lead to the impoverishment of vast numbers of persons in North America and Western Europe because the leaders of those countries seem to be virtue-signaling CO2-reduction race to limit and eventually ban the use of fossil fuels.
If David Stove were still with us, he would probably say what I have just said about the current misperception, given his penchant for iconoclasm. But where would that leave his “naive realism” about scientific progress? He would have to reject it. In fact, knowing (as he undoubtedly did) of the erroneous belief in and explanation a geocentric universe, he should have rejected his “naive realism” about scientific progress before taking Popper et al. to task for their skepticism about the validity of new scientific knowledge.
Yes, scientific knowledge accrues. It accrues because knowledge (to a scientist) is ineluctably incomplete; there is always a deeper or more detailed explanation of phenomena to be found. The search for the deeper or more detailed explanation usually turns up new facts (or surmises) about physical existence.
But scientific knowledge actually accrues only when new “knowledge” is treated as provisional and tested rigorously. Even then, it may still prove to be wrong. That which isn’t disproved (falsified) adds to the store of (provisional) scientific knowledge. But, as Stove fails to acknowledge, much old “knowledge” hasn’t survived, and some current “knowledge” shouldn’t survive (e.g., the CO2-driven theory of “climate change”).
Here is the argument that Stove should have made:
Think of all of the ink, paper, and pixels that could been saved if Stove had thought more carefully about science and issued a PowerPoint slide instead of a book.
Related post: Deduction, Induction, and Knowledge
Much has been written (pro and con) about the “pause” in global warming climate change the synthetic reconstruction of Earth’s “average” temperature from 1997 to 2012. That pause was followed fairly quickly by a new one, which began in 2014 and is still in progress (if a pause can be said to exhibit progress).
Well, I have a better one for you, drawn from the official temperature records for Austin, Texas — the festering Blue wound in the otherwise healthy Red core of Texas. (Borrowing Winston Churchill’s formulation, Austin is the place up with which I have put for 18 years — and will soon quit, to my everlasting joy.)
There is a continuous record of temperatures in central Austin from January 1903 to the present. The following graph is derived from that record:

A brief inspection of the graph reveals the obvious fact that there was a pause in Austin’s average temperature from (at least) 1903 until sometime in 1999. Something happened in 1999 to break the pause. What was it? It couldn’t have been “global warming”, the advocates of which trace back to the late 1800s (despite some prolonged cooling periods after that).
Austin’s weather station was relocated in 1999, which might have had something to do with it. More likely, the illusory jump in Austin’s temperature was caused by the urban heat-island effect induced by the growth of Austin’s population, which increased markedly from 1999 to 2000, and has been rising rapidly ever since.
Related reading:
Paul Homewood, “Washington’s New Climate ‘Normals’ Are Hotter“, Not a Lot of People Know That, May 6, 2021 (wherein the writer shows that the rise in D.C.’s new “normal” temperatures is due to the urban heat-island effect)
H. Sterling Burnett, “Sorry, CBS, NOAA’s ‘U.S. Climate Normals’ Report Misrepresents the Science“, Climate Realism, May 7, 2021 (just what the title says)
I have written a lot about modeling and science. (See the long list of posts at “Modeling, Science, and ‘Reason’“.) I have said, more than once, that modeling isn’t science. What I should have said — though it was always implied — is that a model isn’t scientific if it is merely synthetic.
What do I mean by that? Here is an example by way of contrast. The famous equation E = mc2 is an synthetic model in that it is derived Einstein’s special theory of relativity (and other physical equations). But it is also an empirical model in that the relationship between mass (m) and energy (E) can also be confirmed by observation (given suitable instruments).
On the other hand, a complex model of the U.S. economy, a model of Earth’s “average” temperature (called misleadingly a climate model), or a model of combat (to give a few examples) is only synthetic.
Why do I say that a complex model (of the kind mentioned above) is only synthetic? Such a model consists of a large number of modules, each of which is mathematical formulation of some aspect of the larger phenomenon being modeled. Here’s a simple example: An encounter between a submarine and a surface ship, where the outcome is expressed as the probability that the submarine will sink the surface ship. The outcome could be expressed in this way:
S = D x F x H x K x C, where S = probability that submarine sinks surface ship, which is the product of:
D = probability that submarine detects surface ship within torpedo range
F = probability that, given detection, submarine is able to “fix” the target and fire a torpedo (or salvo of them)
H = probability that, given the firing of a torpedo (or salvo), the surface ship is hit
K = probability that, given a hit (or hits), the surface ship is sunk
C = probability that the submarine survives efforts to find and nullify it before it can detect a surface ship
This is a simple model by comparison with a model of the U.S. economy, a global climate model, or a model of a battle involving large numbers of various kinds of weapons. In fact, it is a simplistic model of combat. Each of the modules could be decomposed into many sub-modules; for example, the module for D could consist of sub-modules for sonar accuracy, sonar operator acuity, acoustic conditions in the area of operation, countermeasures deployed by the target, etc.. In any event, the module for D will consist of a mathematical relationship, based perhaps on some statistics collected from tests or exercises (i.e., not actual combat). The mathematical relationship will encompass many assumptions (mainly implicit ones) about sonar accuracy, sonar operator acuity, etc. The same goes for the other modules — C, in particular, which encompasses all of the effects of D, F, H, and K — at a minimum.
In sum, the number of unknowns completely swamps the number of knowns. There is nothing close to certainty about the model — or any model of its kind. (In the case of the model of S, for example, relatively small errors — say, 25 percent from the actual value of each variable — can yield an estimate of S that is three times greater than or one-third as much as the actual value of S.) The mathematical operations involved do nothing to resolve the uncertainty, they merely multiply it. But the mathematical operations nevertheless convey the appearance of certainty because they yield numbers. The numbers merely represent a lot of guesses, but they seem authoritative because numbers mesmerize most people — even scientists who should be always be skeptical of them.
Despite all of that, analysts have for many decades been producing — and decision-makers have been consuming — the results of such models as the basis for choosing defense systems. Models of similar complexity have been and are being used in making decisions about a broad range of policies affecting the economy, health care, transportation, education, the environment, the climate (i.e., “global warming”), and on into the night.
The unfounded confidence that modelers have in their models, because the models produce numbers, captivates most decision-makers, who simply want answers. And so, modelers will go to ridiculous extremes. One not untypical example that I recall from my days as an in-house critic of analysts’ work is the model that purported to compare competing weapons (on of which was still in development) based on their relative contribution to the outcome of a hypothetical battle. The specific measure was the movement of the forward edge of the battle area (FEBA) to within a yard.
Global climate models are like that warfare model: Their creators pretend that they can estimate the change in the average temperature of the globe to within less than a tenth of a degree. If you believe that, I have a bridge to sell you.
Related reading: Robert L. Bradley Jr. “Climate Models: Worse than Nothing?“, Watts Up With That?, June 23, 2021 (Yes. See below.)
Related pages:
