I have written many times over the years about what will happen to liberty in America the next time a Democrat is in the White House and Congress is controlled by Democrats. Many others have written or spoken about the same, dire scenario. Recently, for example, Victor Davis Hanson and Danielle Pletka addressed the threat to liberty that lies ahead if Donald Trump is succeeded by Joe Biden, in tandem with a Democrat takeover of the Senate. This post reprises my many posts about the clear and present danger to liberty if Trump is defeated and the Senate flips, and adds some points suggested by Hanson and Pletka. There’s much more to be said, I’m sure, but what I have to say here should be enough to make every liberty-loving American vote for Trump — even those who abhor the man’s persona.
Court Packing
One of the first things on the agenda will be to enlarge the Supreme Court and fill the additional seats with justices who can be counted on to support the following policies discussed below, should those policies get to the Supreme Court. (If they don’t, they will be upheld in lower courts or go unchallenged because challenges will be perceived as futile.)
Abolition of the Electoral College
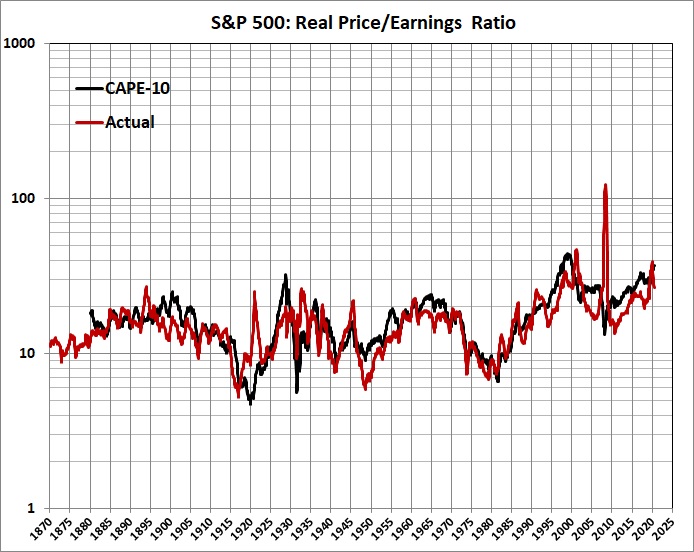
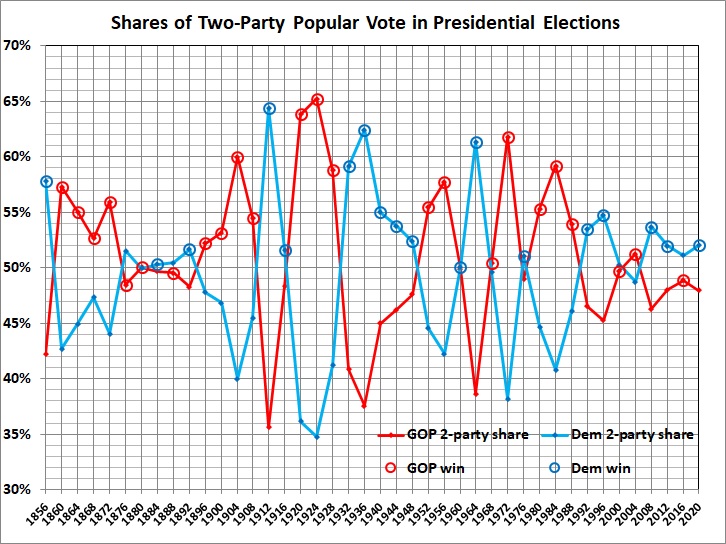
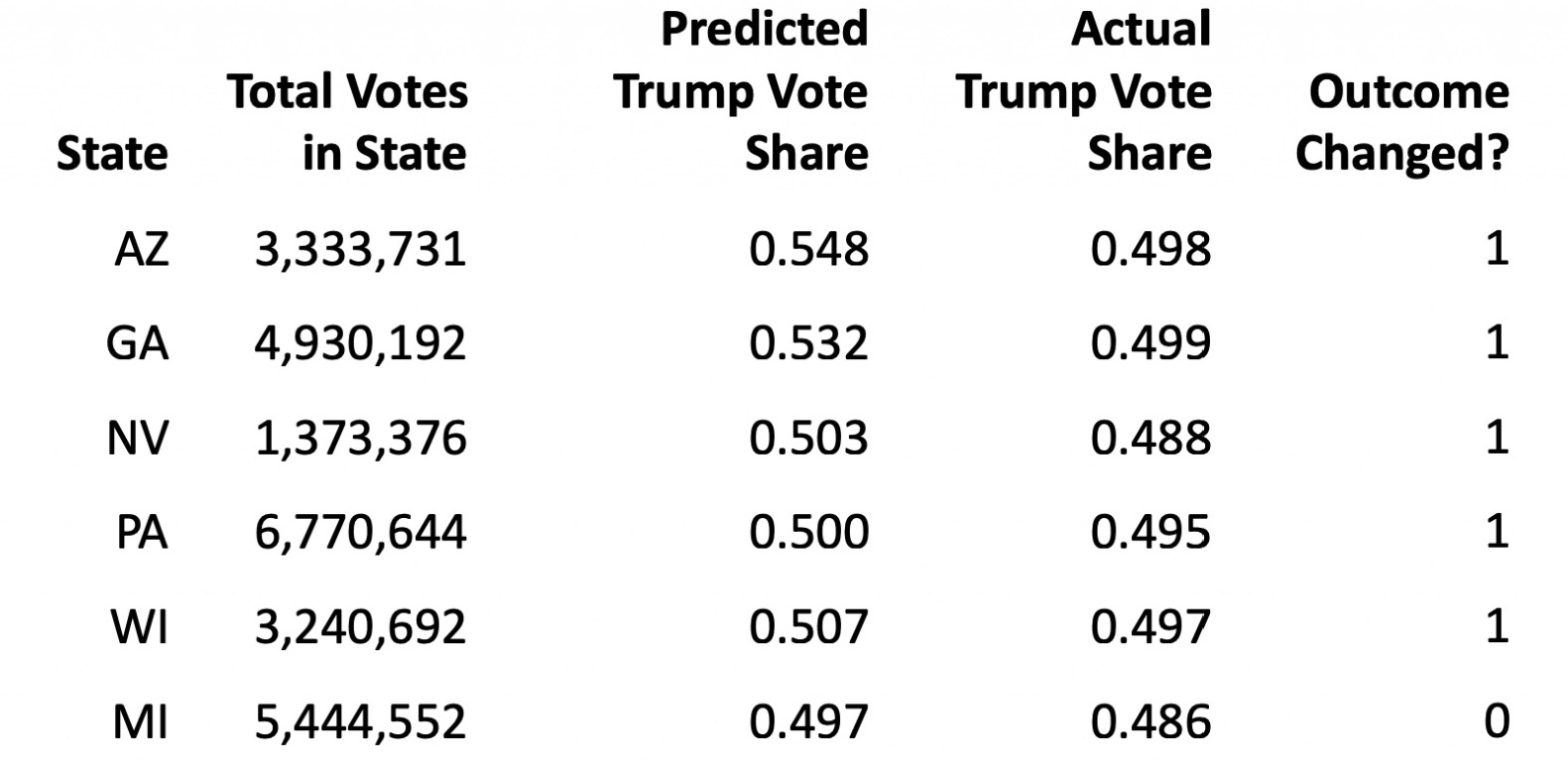
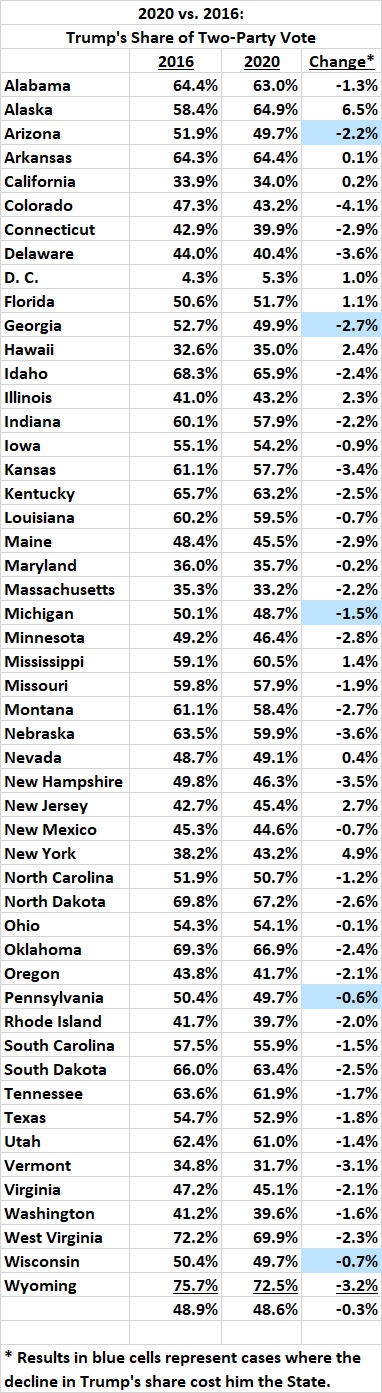
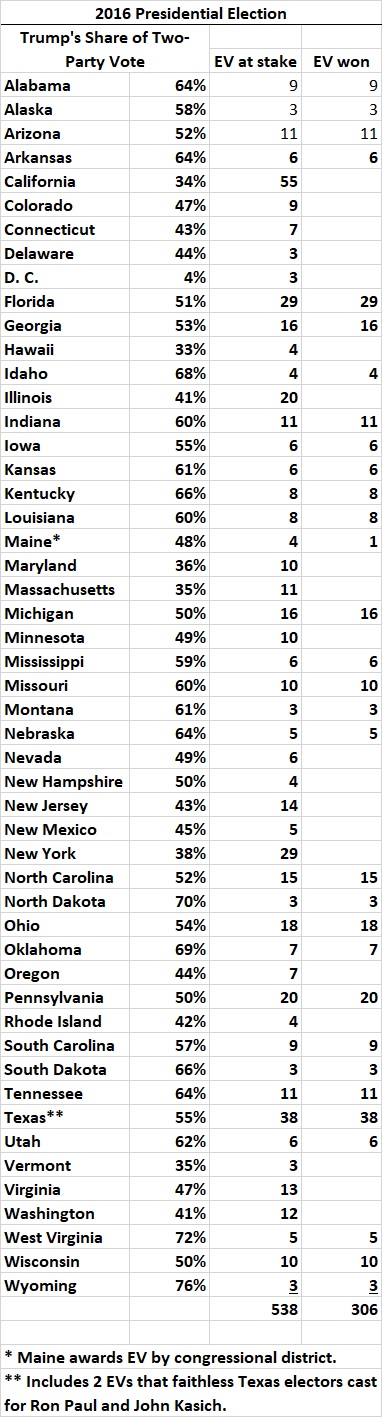
The Electoral College helps to protect the sovereignty of less-populous States from oppression by more-populous States. This has become especially important with the electoral shift that has seen California, New York, and other formerly competitive States slide into leftism. The Electoral College therefore causes deep resentment on the left when it yields a Republican president who fails to capture a majority of the meaningless nationwide popular vote, as Donald Trump failed (by a large margin) in 2016), despite lopsided victories by H. Clinton in California, New York, etc.
The Electoral College could be abolished formally by an amendment to the Constitution. But amending the Constitution by that route would take years, and probably wouldn’t succeed because it would be opposed by too many State legislatures.
The alternative, which would succeed with Democrat control of Congress and a complaisant Supreme Court, is a multi-State compact to this effect: The electoral votes of each member State will be cast for the candidate with the most popular votes, nationwide, regardless of the popular vote in the member State. This would work to the advantage of a Democrat who loses narrowly in a State where the legislature and governor’s mansion is controlled by Democrats – which is the whole idea.
Some pundits deny that the scheme would favor Democrats, but the history of presidential elections contradicts them.
Electorate Packing
If you’re going to abolish the Electoral College, you want to ensure a rock-solid hold on the presidency and Congress. What better way to do that than to admit Puerto Rico and the District of Columbia? Residents of D.C. already vote in presidential elections, but the don’t have senators and or a voting representative in the House. Statehood would give them those things. And you know which party’s banner the additional senators and representative would fly.
Admitting Puerto Rico would be like winning the trifecta (for Democrats): a larger popular-vote majority for Democrat presidential candidates, two more Democrat senators, and five more Democrat representatives in the House.
“Climate Change”
The “science” of “climate change” amounts to little more than computer models that can’t even “predict” recorded temperatures accurately because the models are based mainly on the assumption that CO2 (a minor greenhouse gas) drives the atmosphere’s temperature. This crucial assumption rests on a coincidence – rising temperatures from the late 1970s and rising levels of atmospheric CO2. But atmospheric CO2 has been far higher in earlier geological eras, while Earth’s temperature hasn’t been any higher than it is now. Yes, CO2 has been rising since the latter part of the 19th century, when industrialization began in earnest. Despite that, temperatures have fluctuated up and down for most of the past 150 years. (Some so-called scientists have resolved that paradox by adjusting historical temperatures to make them look lower than the really are.)
The deeper and probably more relevant causes of atmospheric temperature are to be found in the Earth’s core, magma flow, plate dynamics, ocean currents and composition, magnetic field, exposure to cosmic radiation, and dozens of other things that — to my knowledge — are ignored by climate models. Moreover, the complexity of the interactions of such factors, and others that are usually included in climate models cannot possibly be modeled.
The urge to “do something” about “climate change” is driven by a combination of scientific illiteracy, power-lust, and media-driven anxiety.
As a result, trillions of dollars have been and will be wasted on various “green” projects. These include but are far from limited to the replacement of fossil fuels by “renewables”, and the crippling of industries that depend on fossil fuels. Given that CO2 does influence atmospheric temperature slightly, it’s possible that such measures will have a slight effect on Earth’s temperature, even though the temperature rise has been beneficial (e.g., longer growing seasons; fewer deaths from cold weather, which kills more people than hot weather).
The main result of futile effort to combat “climate change” will be greater unemployment and lower real incomes for most Americans — except for the comfortable elites who press such policies.
Freedom of Speech
Legislation forbidding “hate speech” will be upheld by the packed Court. “Hate speech” will be whatever the bureaucrats who are empowered to detect and punish it say it is. And the bureaucrats will be swamped with complaints from vindictive leftists.
When the system is in full swing (which will take only a few years) it will be illegal to criticize, even by implication, such things as illegal immigration, same-sex marriage, transgenderism, anthropogenic global warming, or the confiscation of firearms. Violations will be enforced by huge fines and draconian prison sentences (sometimes in the guise of “re-education”).
Any hint of Christianity and Judaism will be barred from public discourse, and similarly punished. Islam will be held up as a model of unity and tolerance – at least until elites begin to acknowledge that Muslims are just as guilty of “incorrect thought” as persons of other religions and person who uphold the true spirit of the Constitution.
Reverse Discrimination
This has been in effect for several decades, as jobs, promotions, and college admissions have been denied the most capable persons in favor or certain “protected group” – manly blacks and women.
Reverse-discrimination “protections” will be extended to just about everyone who isn’t a straight, white male of European descent. And they will be enforced more vigorously than ever, so that employers will bend over backward to favor “protected groups” regardless of the effects on quality and quantity of output. That is, regardless of how such policies affect the general well-being of all Americans. And, of course, the heaviest burden – unemployment or menial employment – will fall on straight, white males of European descent. Except, of course, for the straight while males of European descent who are among the political, bureaucratic, and management elites who favor reverse discrimination.
Rule of Law
There will be no need for protests riots because police departments will become practitioners and enforcers of reverse discrimination (as well as “hate speech” violations and attempts to hold onto weapons for self-defense). This will happen regardless of the consequences, such as a rising crime rate, greater violence against whites and Asians, and flight from the cities (which will do little good because suburban police departments will also be co-opted).
Sexual misconduct (as defined by the alleged victim), will become a crime, and any straight, male person will be found guilty of it on the uncorroborated testimony of any female who claims to have been the victim of an unwanted glance, touch (even if accidental), innuendo (as perceived by the victim), etc.
There will be parallel treatment of the “crimes” of racism, anti-Islamism, nativism, and genderism.
Health Care
All health care and health-care related products and services (e.g., drug research) will be controlled and rationed by an agency of the federal government. Private care will be forbidden, though ready access to doctors, treatments, and medications will be provided for high officials and other favored persons.
Drug research – and medical research, generally – will dwindle in quality and quantity. There will be fewer doctors and nurses who are willing to work in a regimented system.
The resulting health-care catastrophe that befalls most of the populace (like that of the UK) will be shrugged off as a residual effect of “capitalist” health care.
Regulation
The regulatory regime, which already imposes a deadweight loss of 10 percent of GDP, will rebound with a vengeance, touching every corner of American life and regimenting all businesses except those daring to operate in an underground economy. The quality and variety of products and services will decline – another blow to Americans’ general well-being.
Taxation
Incentives to produce more and better products and services will be further blunted by increases on corporate profits, a more “progressive” structure of marginal tax rates (i.e., soaking the “rich”), and — perhaps worst of all — taxing wealth. Such measures will garner votes by appealing to economic illiterates, the envious, social-justice warriors, and guilt-ridden elites who can afford the extra taxes but don’t understand how their earnings and wealth foster economic growth and job creation. (A Venn diagram would depict almost the complete congruence of economic illiterates, the envious, social-justice warriors, and guilt-ridden elites.)
Government Spending and National Defense
The dire economic effects of the foregoing policies will be compounded by massive increases in government spending on domestic welfare programs, which reward the unproductive at the expense of the productive. All of this will suppress investment in business formation and expansion, and in professional education and training. As a result, the real rate of economic growth will approach zero, and probably become negative.
Because of the emphasis on domestic welfare programs, the United States will maintain token armed forces (mainly for the purpose of suppressing domestic uprisings). The U.S. will pose no threat to the new superpowers — Russia and China. They won’t threaten the U.S. militarily as long as the U.S. government acquiesces in their increasing dominance.
Immigration
Illegal immigration will become legal, and all illegal immigrants now in the country – and the resulting flood of new immigrants — will be granted citizenship and all associated rights. The right to vote, of course, is the right that Democrats most dearly want to bestow because most of the newly-minted citizens can be counted on to vote for Democrats. The permanent Democrat majority will ensure permanent Democrat control of the White House and both houses of Congress.
Future Elections and the Death of Democracy
Despite the prospect of a permanent Democrat majority, Democrats won’t stop there. In addition to the restrictions on freedom of speech discussed above, there will be election laws requiring candidates to pass ideological purity tests by swearing fealty to the “law of the land” (i.e., unfettered immigration, same-sex marriage, freedom of gender choice for children, etc., etc., etc.). Those who fail such a test will be barred from holding any kind of public office, no matter how insignificant.