This post is based on a paper that I wrote 38 years ago. The subject then was the bankruptcy of warfare models, which shows through in parts of this post. I am trying here to generalize the message to encompass all complex, synthetic models (defined below). For ease of future reference, I have created a page that includes links to this post and the many that are listed at the bottom.
THE METAPHYSICS OF MODELING
Alfred North Whitehead said in Science and the Modern World (1925) that “the certainty of mathematics depends on its complete abstract generality” (p. 25). The attraction of mathematical models is their apparent certainty. But a model is only a representation of reality, and its fidelity to reality must be tested rather than assumed. And even if a model seems faithful to reality, its predictive power is another thing altogether. We are living in an era when models that purport to reflect reality are given credence despite their lack of predictive power. Ironically, those who dare point this out are called anti-scientific and science-deniers.
To begin at the beginning, I am concerned here with what I will call complex, synthetic models of abstract variables like GDP and “global” temperature. These are open-ended, mathematical models that estimate changes in the variable of interest by attempting to account for many contributing factors (parameters) and describing mathematically the interactions between those factors. I call such models complex because they have many “moving parts” — dozens or hundreds of sub-models — each of which is a model in itself. I call them synthetic because the estimated changes in the variables of interest depend greatly on the selection of sub-models, the depictions of their interactions, and the values assigned to the constituent parameters of the sub-models. That is to say, compared with a model of the human circulatory system or an internal combustion engine, a synthetic model of GDP or “global” temperature rests on incomplete knowledge of the components of the systems in question and the interactions among those components.
Modelers seem ignorant of or unwilling to acknowledge what should be a basic tenet of scientific inquiry: the complete dependence of logical systems (such as mathematical models) on the underlying axioms (assumptions) of those systems. Kurt Gödel addressed this dependence in his incompleteness theorems:
Gödel’s incompleteness theorems are two theorems of mathematical logic that demonstrate the inherent limitations of every formal axiomatic system capable of modelling basic arithmetic….
The first incompleteness theorem states that no consistent system of axioms whose theorems can be listed by an effective procedure (i.e., an algorithm) is capable of proving all truths about the arithmetic of natural numbers. For any such consistent formal system, there will always be statements about natural numbers that are true, but that are unprovable within the system. The second incompleteness theorem, an extension of the first, shows that the system cannot demonstrate its own consistency.
There is the view that Gödel’s theorems aren’t applicable in fields outside of mathematical logic. But any quest for certainty about the physical world necessarily uses mathematical logic (which includes statistics).
This doesn’t mean that the results of computational exercises are useless. It simply means that they are only as good as the assumptions that underlie them; for example, assumptions about relationships between parameters, assumptions about the values of the parameters, and assumptions as to whether the correct parameters have been chosen (and properly defined) in the first place.
There is nothing new in that, certainly nothing that requires Gödel’s theorems by way of proof. It has long been understood that a logical argument may be valid — the conclusion follows from the premises — but untrue if the premises (axioms) are untrue. But it bears repeating — and repeating.
REAL MODELERS AT WORK
There have been mathematical models of one kind and another for centuries, but formal models weren’t used much outside the “hard sciences” until the development of microeconomic theory in the 19th century. Then came F.W. Lanchester, who during World War I devised what became known as Lanchester’s laws (or Lanchester’s equations), which are
mathematical formulae for calculating the relative strengths of military forces. The Lanchester equations are differential equations describing the time dependence of two [opponents’] strengths A and B as a function of time, with the function depending only on A and B.
Lanchester’s equations are nothing more than abstractions that must be given a semblance of reality by the user, who is required to make myriad assumptions (explicit and implicit) about the factors that determine the “strengths” of A and B, including but not limited to the relative killing power of various weapons, the effectiveness of opponents’ defenses, the importance of the speed and range of movement of various weapons, intelligence about the location of enemy forces, and commanders’ decisions about when, where, and how to engage the enemy. It should be evident that the predictive value of the equations, when thus fleshed out, is limited to small, discrete engagements, such as brief bouts of aerial combat between two (or a few) opposing aircraft. Alternatively — and in practice — the values are selected so as to yield results that mirror what actually happened (in the “replication” of a historical battle) or what “should” happen (given the preferences of the analyst’s client).
More complex (and realistic) mathematical modeling (also known as operations research) had seen limited use in industry and government before World War II. Faith in the explanatory power of mathematical models was burnished by their use during the war, where such models seemed to be of aid in the design of more effective tactics and weapons.
But the foundation of that success wasn’t the mathematical character of the models. Rather, it was the fact that the models were tested against reality. Philip M. Morse and George E. Kimball put it well in Methods of Operations Research (1946):
Operations research done separately from an administrator in charge of operations becomes an empty exercise. To be valuable it must be toughened by the repeated impact of hard operational facts and pressing day-by-day demands, and its scale of values must be repeatedly tested in the acid of use. Otherwise it may be philosophy, but it is hardly science. [Op cit., p. 10]
A mathematical model doesn’t represent scientific knowledge unless its predictions can be and have been tested. Even then, a valid model can represent only a narrow slice of reality. The expansion of a model beyond that narrow slice requires the addition of parameters whose interactions may not be well understood and whose values will be uncertain.
Morse and Kimball accordingly urged “hemibel thinking”:
Having obtained the constants of the operations under study … we compare the value of the constants obtained in actual operations with the optimum theoretical value, if this can be computed. If the actual value is within a hemibel ( … a factor of 3) of the theoretical value, then it is extremely unlikely that any improvement in the details of the operation will result in significant improvement. [When] there is a wide gap between the actual and theoretical results … a hint as to the possible means of improvement can usually be obtained by a crude sorting of the operational data to see whether changes in personnel, equipment, or tactics produce a significant change in the constants. [Op cit., p. 38]
Should we really attach little significance to differences of less than a hemibel? Consider a five-parameter model involving the conditional probabilities of detecting, shooting at, hitting, and killing an opponent — and surviving, in the first place, to do any of these things. Such a model can easily yield a cumulative error of a hemibel (or greater), given a twenty-five percent error in the value each parameter. (Mathematically, 1.255 = 3.05; alternatively, 0.755 = 0.24, or about one-fourth.)
ANTI-SCIENTIFIC MODELING
What does this say about complex, synthetic models such as those of economic activity or “climate change”? Any such model rests on the modeler’s assumptions as to the parameters that should be included, their values (and the degree of uncertainty surrounding them), and the interactions among them. The interactions must be modeled based on further assumptions. And so assumptions and uncertainties — and errors — multiply apace.
But the prideful modeler (I have yet to meet a humble one) will claim validity if his model has been fine-tuned to replicate the past (e.g., changes in GDP, “global” temperature anomalies). But the model is useless unless it predicts the future consistently and with great accuracy, where “great” means accurately enough to validly represent the effects of public-policy choices (e.g., setting the federal funds rate, investing in CO2 abatement technology).
Macroeconomic Modeling: A Case Study
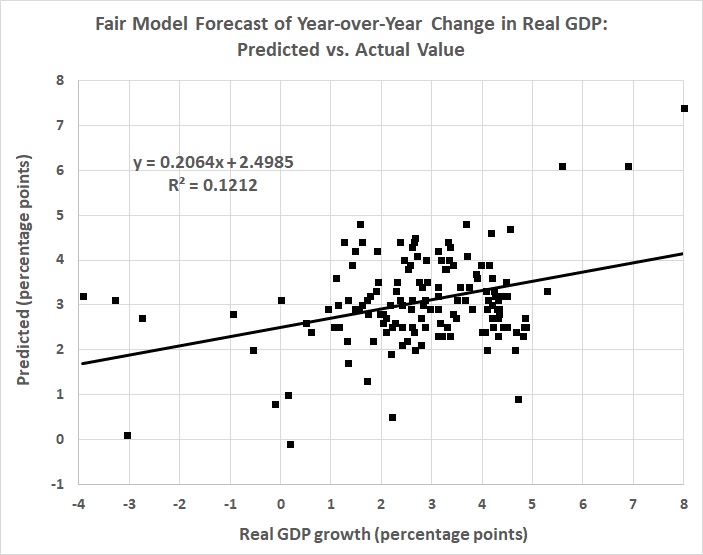
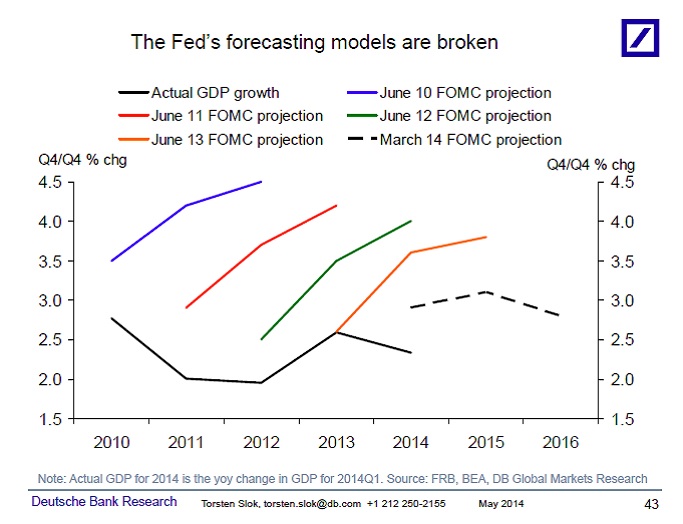
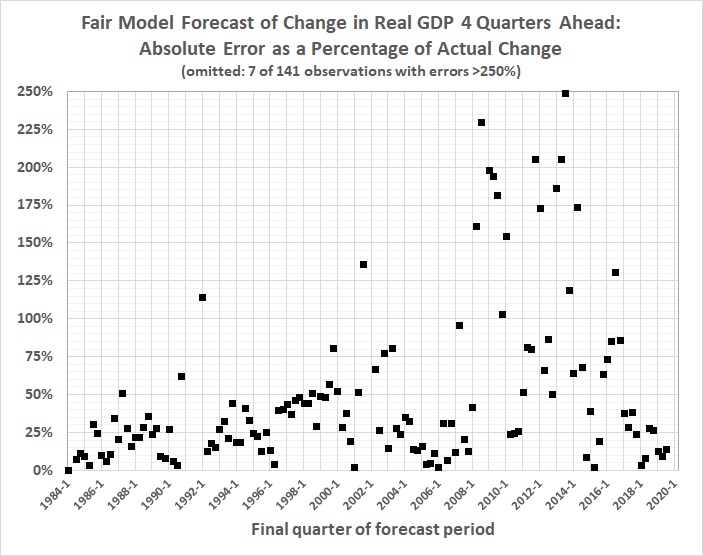
In macroeconomics, for example, there is Professor Ray Fair, who teaches macroeconomic theory, econometrics, and macroeconometric modeling at Yale University. He has been plying his trade at prestigious universities since 1968, first at Princeton, then at MIT, and since 1974 at Yale. Professor Fair has since 1983 been forecasting changes in real GDP — not decades ahead, just four quarters (one year) ahead. He has made 141 such forecasts, the earliest of which covers the four quarters ending with the second quarter of 1984, and the most recent of which covers the four quarters ending with the second quarter of 2019. The forecasts are based on a model that Professor Fair has revised many times over the years. The current model is here. His forecasting track record is here.) How has he done? Here’s how:
1. The median absolute error of his forecasts is 31 percent.
2. The mean absolute error of his forecasts is 69 percent.
3. His forecasts are rather systematically biased: too high when real, four-quarter GDP growth is less than 3 percent; too low when real, four-quarter GDP growth is greater than 3 percent.
4. His forecasts have grown generally worse — not better — with time. Recent forecasts are better, but still far from the mark.
Thus:
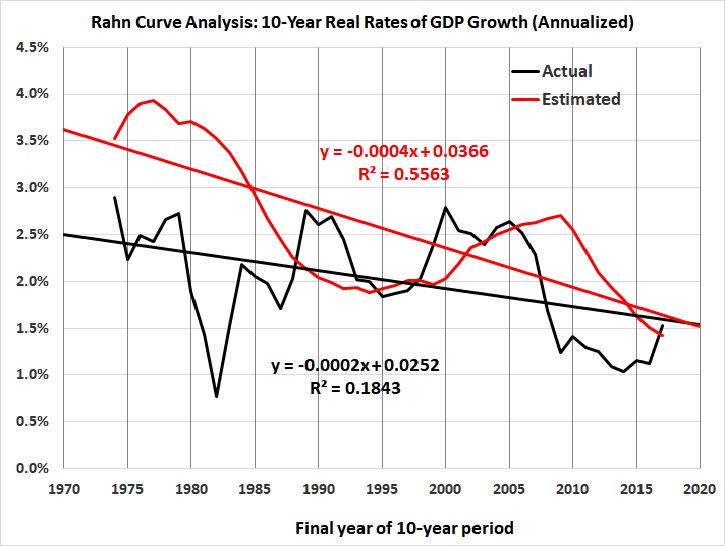
This and the next two graphs were derived from The Forecasting Record of the U.S. Model, Table 4: Predicted and Actual Values for Four-Quarter Real Growth, at Prof. Fair’s website. The vertical axis of this graph is truncated for ease of viewing, as noted in the caption.
You might think that Fair’s record reflects the persistent use of a model that’s too simple to capture the dynamics of a multi-trillion-dollar economy. But you’d be wrong. The model changes quarterly. This page lists changes only since late 2009; there are links to archives of earlier versions, but those are password-protected.
As for simplicity, the model is anything but simple. For example, go to Appendix A: The U.S. Model: July 29, 2016, and you’ll find a six-sector model comprising 188 equations and hundreds of variables.
And what does that get you? A weak predictive model:

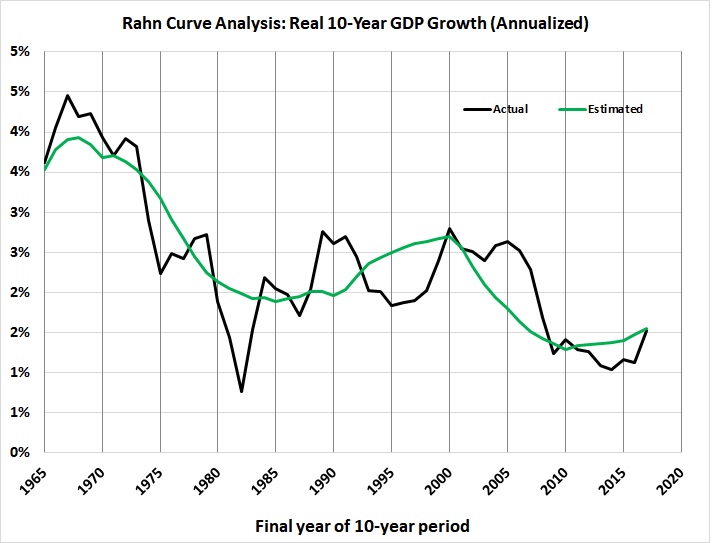
It fails a crucial test, in that it doesn’t reflect the downward trend in economic growth:

General Circulation Models (GCMs) and “Climate Change”
As for climate models, Dr. Tim Ball writes about a
fascinating 2006 paper by Essex, McKitrick, and Andresen asked, “Does a Global Temperature Exist.” Their introduction sets the scene,
It arises from projecting a sampling of the fluctuating temperature field of the Earth onto a single number (e.g. [3], [4]) at discrete monthly or annual intervals. Proponents claim that this statistic represents a measurement of the annual global temperature to an accuracy of ±0.05 ◦C (see [5]). Moreover, they presume that small changes in it, up or down, have direct and unequivocal physical meaning.
The word “sampling” is important because, statistically, a sample has to be representative of a population. There is no way that a sampling of the “fluctuating temperature field of the Earth,” is possible….
… The reality is we have fewer stations now than in 1960 as NASA GISS explain (Figure 1a, # of stations and 1b, Coverage)….
Not only that, but the accuracy is terrible. US stations are supposedly the best in the world but as Anthony Watt’s project showed, only 7.9% of them achieve better than a 1°C accuracy. Look at the quote above. It says the temperature statistic is accurate to ±0.05°C. In fact, for most of the 406 years when instrumental measures of temperature were available (1612), they were incapable of yielding measurements better than 0.5°C.
The coverage numbers (1b) are meaningless because there are only weather stations for about 15% of the Earth’s surface. There are virtually no stations for
- 70% of the world that is oceans,
- 20% of the land surface that are mountains,
- 20% of the land surface that is forest,
- 19% of the land surface that is desert and,
- 19% of the land surface that is grassland.
The result is we have inadequate measures in terms of the equipment and how it fits the historic record, combined with a wholly inadequate spatial sample. The inadequacies are acknowledged by the creation of the claim by NASA GISS and all promoters of anthropogenic global warming (AGW) that a station is representative of a 1200 km radius region.
I plotted an illustrative example on a map of North America (Figure 2).

Figure 2
Notice that the claim for the station in eastern North America includes the subarctic climate of southern James Bay and the subtropical climate of the Carolinas.
However, it doesn’t end there because this is only a meaningless temperature measured in a Stevenson Screen between 1.25 m and 2 m above the surface….
The Stevenson Screen data [are] inadequate for any meaningful analysis or as the basis of a mathematical computer model in this one sliver of the atmosphere, but there [are] even less [data] as you go down or up. The models create a surface grid that becomes cubes as you move up. The number of squares in the grid varies with the naïve belief that a smaller grid improves the models. It would if there [were] adequate data, but that doesn’t exist. The number of cubes is determined by the number of layers used. Again, theoretically, more layers would yield better results, but it doesn’t matter because there are virtually no spatial or temporal data….
So far, I have talked about the inadequacy of the temperature measurements in light of the two- and three-dimensional complexities of the atmosphere and oceans. However, one source identifies the most important variables for the models used as the basis for energy and environmental policies across the world.
Sophisticated models, like Coupled General Circulation Models, combine many processes to portray the entire climate system. The most important components of these models are the atmosphere (including air temperature, moisture and precipitation levels, and storms); the oceans (measurements such as ocean temperature, salinity levels, and circulation patterns); terrestrial processes (including carbon absorption, forests, and storage of soil moisture); and the cryosphere (both sea ice and glaciers on land). A successful climate model must not only accurately represent all of these individual components, but also show how they interact with each other.
The last line is critical and yet impossible. The temperature data [are] the best we have, and yet [they are] completely inadequate in every way. Pick any of the variables listed, and you find there [are] virtually no data. The answer to the question, “what are we really measuring,” is virtually nothing, and what we measure is not relevant to anything related to the dynamics of the atmosphere or oceans.
I am especially struck by Dr. Ball’s observation that the surface-temperature record applies to about 15 percent of Earth’s surface. Not only that, but as suggested by Dr. Ball’s figure 2, that 15 percent is poorly sampled.
And yet the proponents of CO2-forced “climate change” rely heavily on that flawed temperature record because it is the only one that goes back far enough to “prove” the modelers’ underlying assumption, namely, that it is anthropogenic CO2 emissions which have caused the rise in “global” temperatures. See, for example, Dr. Roy Spencer’s “The Faith Component of Global Warming Predictions“, wherein Dr. Spencer points out that the modelers
have only demonstrated what they assumed from the outset. It is circular reasoning. A tautology. Evidence that nature also causes global energy imbalances is abundant: e.g., the strong warming before the 1940s; the Little Ice Age; the Medieval Warm Period. This is why many climate scientists try to purge these events from the historical record, to make it look like only humans can cause climate change.
In fact the models deal in temperature anomalies, that is, departures from a 30-year average. The anomalies — which range from -1.41 to +1.68 degrees C — are so small relative to the errors and uncertainties inherent in the compilation, estimation, and model-driven adjustments of the temperature record, that they must fail Morse and Kimball’s hemibel test. (The model-driven adjustments are, as Dr. Spencer suggests, downward adjustments of historical temperature data for consistency with the models which “prove” that CO2 emissions induce a certain rate of warming. More circular reasoning.)
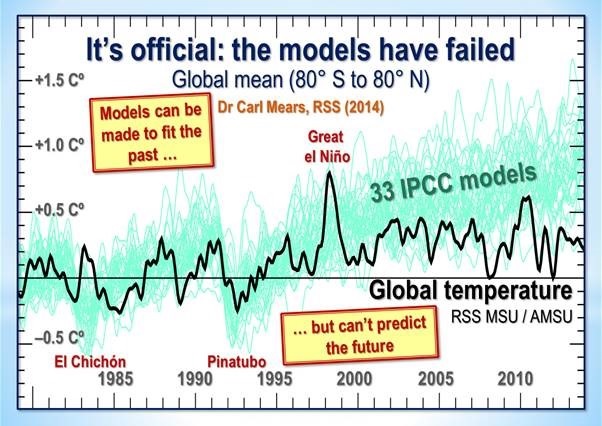
They also fail, and fail miserably, the acid test of predicting future temperatures with accuracy. This failure has been pointed out many times. Dr. John Christy, for example, has testified to that effect before Congress (e.g., this briefing). Defenders of the “climate change” faith have attacked Dr. Christy’s methods and finding, but the rebuttals to one such attack merely underscore the validity of Dr. Christy’s work.
This is from “Manufacturing Alarm: Dana Nuccitelli’s Critique of John Christy’s Climate Science Testimony“, by Mario Lewis Jr.:
Christy’s testimony argues that the state-of-the-art models informing agency analyses of climate change “have a strong tendency to over-warm the atmosphere relative to actual observations.” To illustrate the point, Christy provides a chart comparing 102 climate model simulations of temperature change in the global mid-troposphere to observations from two independent satellite datasets and four independent weather balloon data sets….
To sum up, Christy presents an honest, apples-to-apples comparison of modeled and observed temperatures in the bulk atmosphere (0-50,000 feet). Climate models significantly overshoot observations in the lower troposphere, not just in the layer above it. Christy is not “manufacturing doubt” about the accuracy of climate models. Rather, Nuccitelli is manufacturing alarm by denying the models’ growing inconsistency with the real world.
And this is from Christopher Monckton of Brenchley’s “The Guardian’s Dana Nuccitelli Uses Pseudo-Science to Libel Dr. John Christy“:
One Dana Nuccitelli, a co-author of the 2013 paper that found 0.5% consensus to the effect that recent global warming was mostly manmade and reported it as 97.1%, leading Queensland police to inform a Brisbane citizen who had complained to them that a “deception” had been perpetrated, has published an article in the British newspaper The Guardian making numerous inaccurate assertions calculated to libel Dr John Christy of the University of Alabama in connection with his now-famous chart showing the ever-growing discrepancy between models’ wild predictions and the slow, harmless, unexciting rise in global temperature since 1979….
… In fact, as Mr Nuccitelli knows full well (for his own data file of 11,944 climate science papers shows it), the “consensus” is only 0.5%. But that is by the bye: the main point here is that it is the trends on the predictions compared with those on the observational data that matter, and, on all 73 models, the trends are higher than those on the real-world data….
[T]he temperature profile [of the oceans] at different strata shows little or no warming at the surface and an increasing warming rate with depth, raising the possibility that, contrary to Mr Nuccitelli’s theory that the atmosphere is warming the ocean, the ocean is instead being warmed from below, perhaps by some increase in the largely unmonitored magmatic intrusions into the abyssal strata from the 3.5 million subsea volcanoes and vents most of which Man has never visited or studied, particularly at the mid-ocean tectonic divergence boundaries, notably the highly active boundary in the eastern equatorial Pacific. [That possibility is among many which aren’t considered by GCMs.]
How good a job are the models really doing in their attempts to predict global temperatures? Here are a few more examples:



Mr Nuccitelli’s scientifically illiterate attempts to challenge Dr Christy’s graph are accordingly misconceived, inaccurate and misleading.
I have omitted the bulk of both pieces because this post is already longer than needed to make my point. I urge you to follow the links and read the pieces for yourself.
Finally, I must quote a brief but telling passage from a post by Pat Frank, “Why Roy Spencer’s Criticism is Wrong“:
[H]ere’s NASA on clouds and resolution: “A doubling in atmospheric carbon dioxide (CO2), predicted to take place in the next 50 to 100 years, is expected to change the radiation balance at the surface by only about 2 percent. … If a 2 percent change is that important, then a climate model to be useful must be accurate to something like 0.25%. Thus today’s models must be improved by about a hundredfold in accuracy, a very challenging task.”
Frank’s very long post substantiates what I say here about the errors and uncertainties in GCMs — and the multiplicative effect of those errors and uncertainties. I urge you to read it. It is telling that “climate skeptics” like Spencer and Frank will argue openly, whereas “true believers” work clandestinely to present a united front to the public. It’s science vs. anti-science.
CONCLUSION
In the end, complex, synthetic models can be defended only by resorting to the claim that they are “scientific”, which is a farcical claim when models consistently fail to yield accurate predictions. It is a claim based on a need to believe in the models — or, rather, what they purport to prove. It is, in other words, false certainty, which is the enemy of truth.
Newton said it best:
I do not know what I may appear to the world, but to myself I seem to have been only like a boy playing on the seashore, and diverting myself in now and then finding a smoother pebble or a prettier shell than ordinary, whilst the great ocean of truth lay all undiscovered before me.
Just as Newton’s self-doubt was not an attack on science, neither have I essayed an attack on science or modeling — only on the abuses of both that are too often found in the company of complex, synthetic models. It is too easily forgotten that the practice of science (of which modeling is a tool) is in fact an art, not a science. With this art we may portray vividly the few pebbles and shells of truth that we have grasped; we can but vaguely sketch the ocean of truth whose horizons are beyond our reach.
Related pages and posts:
Climate Change
Modeling and Science
Modeling Is Not Science
Modeling, Science, and Physics Envy
Demystifying Science
Analysis for Government Decision-Making: Hemi-Science, Hemi-Demi-Science, and Sophistry
The Limits of Science (II)
“The Science Is Settled”
The Limits of Science, Illustrated by Scientists
Rationalism, Empiricism, and Scientific Knowledge
Ty Cobb and the State of Science
Is Science Self-Correcting?
Mathematical Economics
Words Fail Us
“Science” vs. Science: The Case of Evolution, Race, and Intelligence
Modeling Revisited
The Fragility of Knowledge
Global-Warming Hype
Pattern-Seeking
Hurricane Hysteria
Deduction, Induction, and Knowledge
A (Long) Footnote about Science
The Balderdash Chronicles
Analytical and Scientific Arrogance
The Pretence of Knowledge
Wildfires and “Climate Change”
Why I Don’t Believe in “Climate Change”
Modeling Is Not Science: Another Demonstration
Ad-Hoc Hypothesizing and Data Mining
Analysis vs. Reality