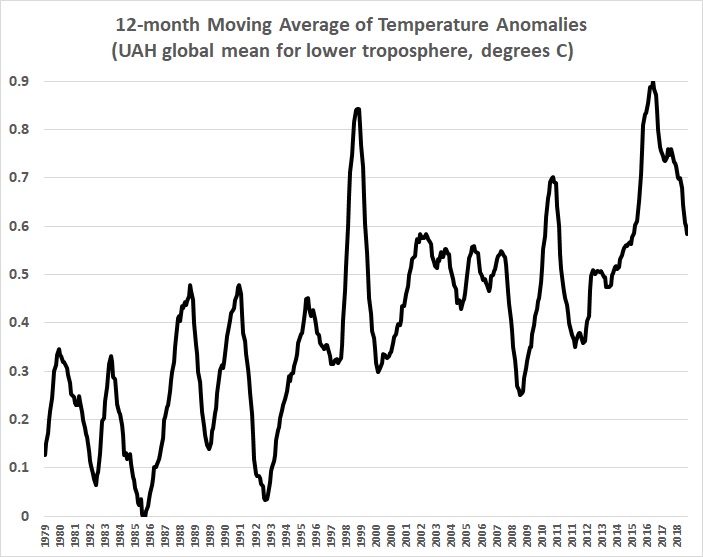
The following graph is a plot of the 12-month moving average of “global” mean temperature anomalies for 1979-2018 in the lower troposphere, as reported by the climate-research unit of the University of Alabama-Huntsville (UAH):
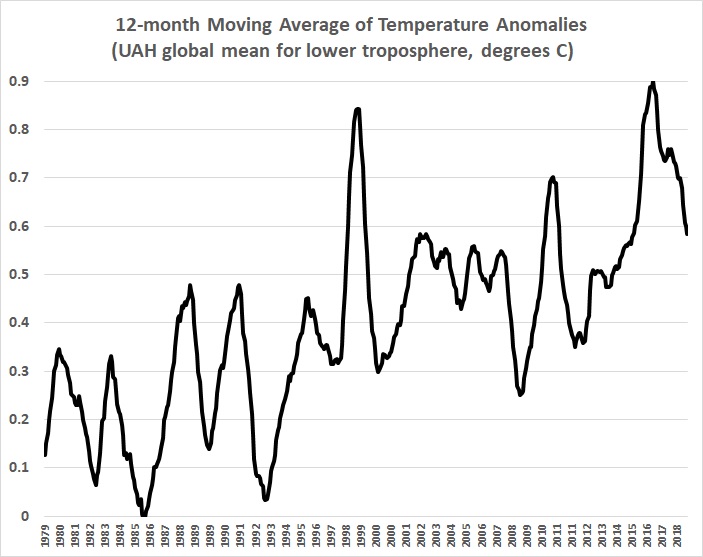
The UAH values, which are derived from satellite-borne sensors, are as close as one can come to an estimate of changes in “global” mean temperatures. The UAH values certainly are more complete and reliable than the values derived from the surface-thermometer record, which is biased toward observations over the land masses of the Northern Hemisphere (the U.S., in particular) — observations that are themselves notoriously fraught with siting problems, urban-heat-island biases, and “adjustments” that have been made to “homogenize” temperature data, that is, to make it agree with the warming predictions of global-climate models.
The next graph roughly resembles the first one, but it’s easier to describe. It represents the fraction of games won by the Oakland Athletics baseball team in the 1979-2018 seasons:

Unlike the “global” temperature record, the A’s W-L record is known with certainty. Every game played by the team (indeed, by all teams in organized baseball) is diligently recorded, and in great detail. Those records yield a wealth of information not only about team records, but also about the accomplishments of the individual players whose combined performance determines whether and how often a team wins its games. Given that information, and much else about which statistics are or could be compiled (records of players in the years and games preceding a season or game; records of each team’s owner, general managers, and managers; orientations of the ballparks in which each team compiled its records; distances to the fences in those ballparks; time of day at which games were played; ambient temperatures, and on and on).
Despite all of that knowledge, there is much uncertainty about how to model the interactions among the quantifiable elements of the game, and how to give weight to the non-quantifiable elements (a manager’s leadership and tactical skills, team spirit, and on and on). Even the professional prognosticators at FiveThirtyEight, armed with a vast compilation of baseball statistics from which they have devised a complex predictive model of baseball outcomes will admit that perfection (or anything close to it) eludes them. Like many other statisticians, they fall back on the excuse that “chance” or “luck” intrudes too often to allow their statistical methods to work their magic. What they won’t admit to themselves is that the results of simulations (such as those employed in the complex model devised by FiveThirtyEight),
reflect the assumptions underlying the authors’ model — not reality. A key assumption is that the model … accounts for all relevant variables….
As I have said, “luck” is mainly an excuse and rarely an explanation. Attributing outcomes to “luck” is an easy way of belittling success when it accrues to a rival.
It is also an easy way of dodging the fact that no model can accurately account for the outcomes of complex systems. “Luck” is the disappointed modeler’s excuse.
If the outcomes of baseball games and seasons could be modeled with great certainly, people wouldn’t bet on those outcomes. The existence of successful models would become general knowledge, and betting would cease, as the small gains that might accrue from betting on narrow odds would be wiped out by vigorish.
Returning now to “global” temperatures, I am unaware of any model that actually tries to account for the myriad factors that influence climate. The pseudo-science of “climate change” began with the assumption that “global” temperatures are driven by human activity, namely the burning of fossil fuels that releases CO2 into the atmosphere. CO2 became the centerpiece of global climate models (GCMs), and everything else became an afterthought, or a non-thought. It is widely acknowledged that cloud formation and cloud cover — obviously important determinants of near-surface temperatures — are treated inadequately (when treated at all). The mechanism by which the oceans absorb heat and transmit it to the atmosphere also remain mysterious. The effect of solar activity on cosmic radiation reaching Earth (and thus on cloud formation) remains is often dismissed despite strong evidence of its importance. Other factors that seem to have little or no weight in GCMs (though they are sometimes estimated in isolation) include plate techtonics, magma flows, volcanic activity, and vegetation.
Despite all of that, builders of GCMs — and the doomsayers who worship them — believe that “global” temperatures will rise to catastrophic readings. The rising oceans will swamp coastal cities; the earth will be scorched. except where it is flooded by massive storms; crops will fail accordingly; tempers will flare and wars will break out more frequently.
There’s just one catch, and it’s a big one. Minute changes in the value of a dependent variable (“global” temperature, in this case) can’t be explained by a model in which key explanatory variables are unaccounted for, about which there is much uncertainty surrounding the values of those explanatory variables that can be accounted for, and about which there is great uncertainty about the mechanisms by which the variables interact. Even an impossibly complete model would be wildly inaccurate given the uncertainty of the interactions among variables and the values of those variables (in the past as well as in the future).
I say “minute changes” because first graph above is grossly misleading. An unbiased depiction of “global” temperatures looks like this:
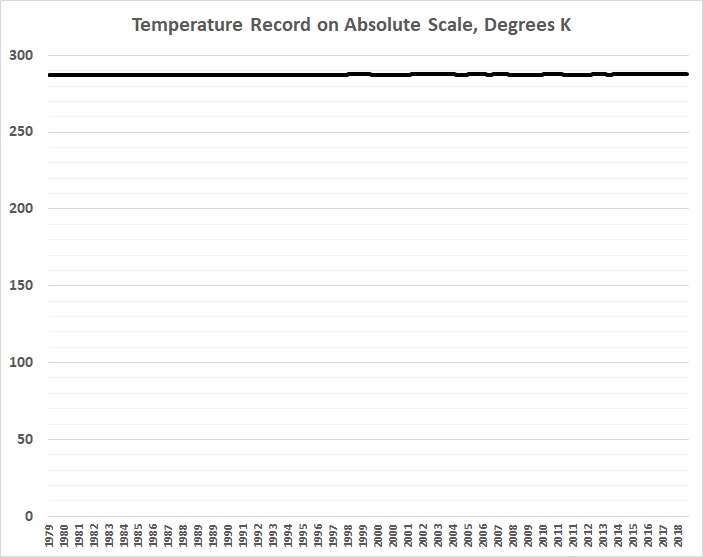
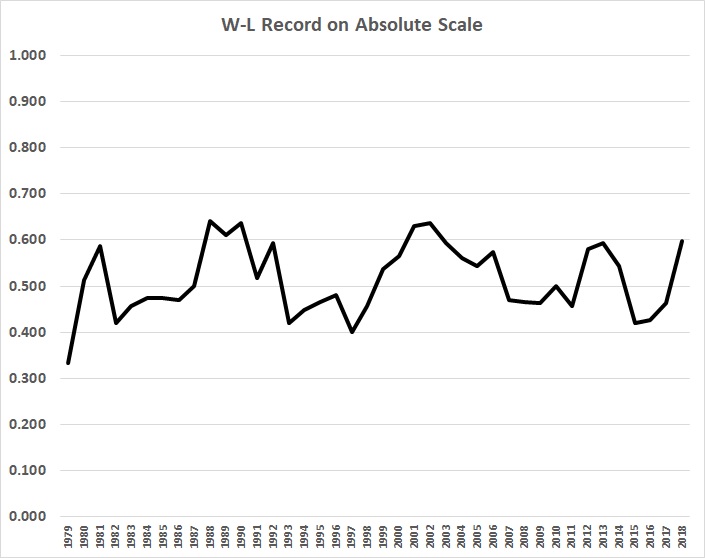
There’s a much better chance of predicting the success or failure of the Oakland A’s, whose record looks like this on an absolute scale:

Just as no rational (unemotional) person should believe that predictions of “global” temperatures should dictate government spending and regulatory policies, no sane bettor is holding his breath in anticipation that the success or failure of the A’s (or any team) can be predicted with bankable certainty.
All of this illustrates a concept known as causal density, which Arnold Kling explains:
When there are many factors that have an impact on a system, statistical analysis yields unreliable results. Computer simulations give you exquisitely precise unreliable results. Those who run such simulations and call what they do “science” are deceiving themselves.
The folks at FiveThirtyEight are no more (and no less) delusional than the creators of GCMs.