Any set of observations has an infinite number of explanations.
— William M. Briggs (Science Is Not the Answer)
The main difference between mathematical formulae and the real world is that the formulae usually reduce open-ended reality to closed-form hypotheses about reality. By closed form, I mean that the hypotheses include only a limited number of factors that determine what is observed (not to mention the inevitable errors in the estimation of the values and weights of those factors).
“Climate change” is exhibit A when it comes to the failure of mathematical formulae to replicate reality. In addition to the many well-researched articles (e.g., here) that challenge the general “scientific” view that CO2 drives atmospheric temperatures, there is Alan Longhurst‘s Doubt and Certainty in Climate Science. Longhurst adduces dozens of factors that influence atmospheric (and oceanic) temperatures — factors that are ignored or insufficiently accounted for in global climate models (GCMs) — while also documenting the wide range of uncertainty about the values and weights of such factors. A more accessible and powerful indictment of “climate change” is the report by John Christy et al., John Christy et al., “A Critical Review of Impacts of Greenhouse Gas Emissions on the U.S. Climate“.
As in too many other cases, GCMs are built upon foundations of sand — their developers’ biases. Examples abound of models equally devoid of reality because they reflect what their builders wish to be true.
One model that is on a par with GCMs in its destructive effects is the Keynsesian multiplier, which for more than 80 years has been used to justify government spending, a vastly destructive undertaking. (For more about biases — known more charitably as assumptions — see Arnold Kling’s post, “The God’s-Eye View of the Economy“.)
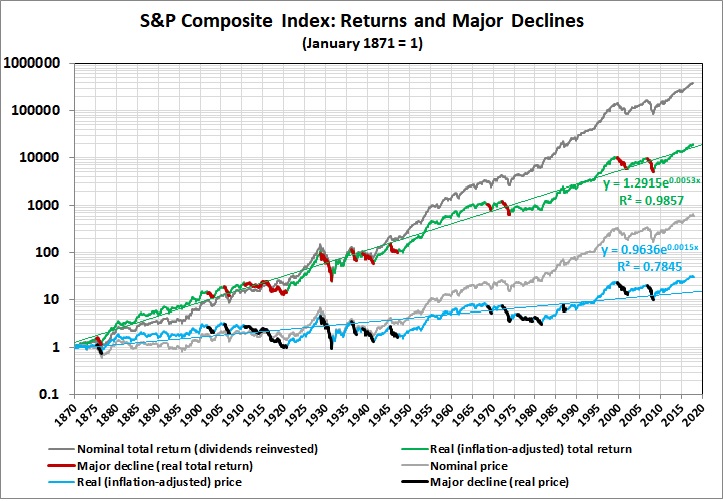
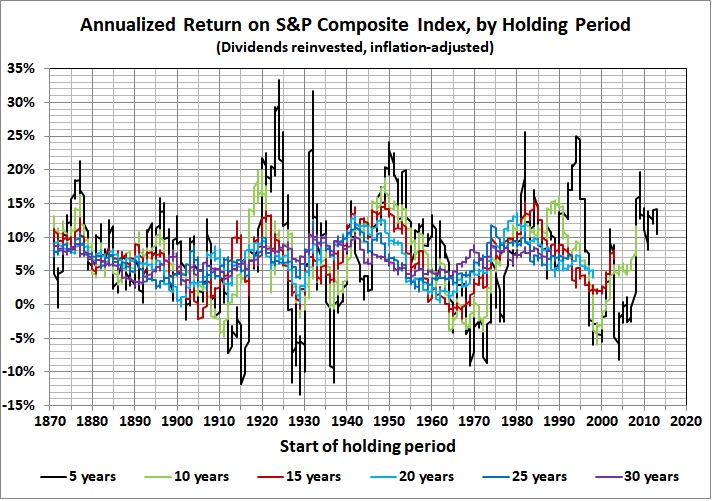
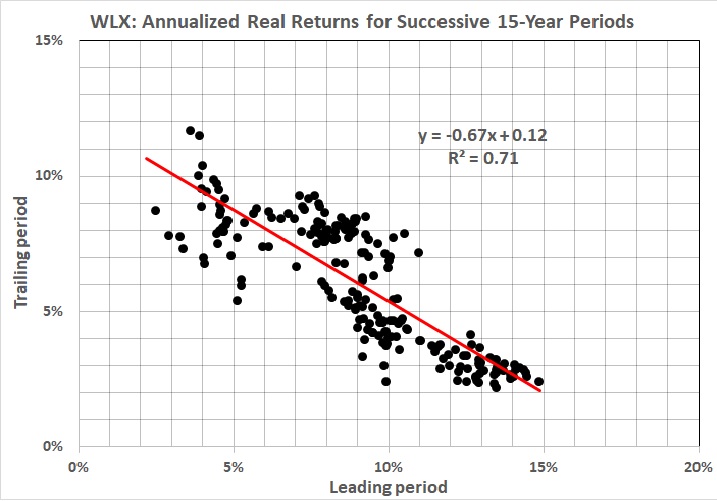
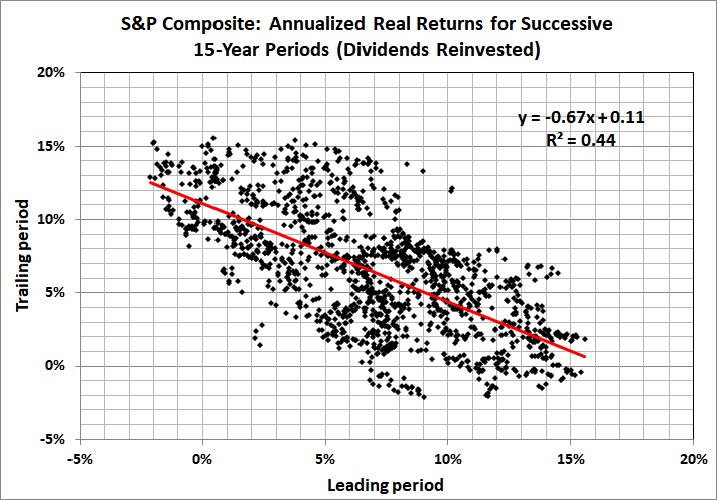
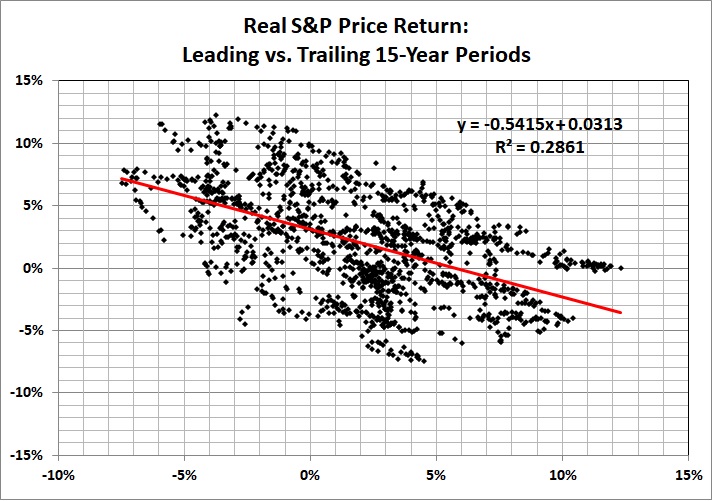
Also in the realm of economics, there is the failure of complex macroeconomic models to predict accurately quarter-to-quarter changes in GDP. I last addressed the subject eight years ago. Here’s key graph from that post:

“Fair” refers to Professor Ray C. Fair of Princeton University, the creator of the model in question. The model isn’t fair (as in fair to middling), it’s a dismal failure. Most of the errors are huge.
If the Fair model seems bad, consider the forecasts of changes in GDP that are published by the Federal Reserve Bank of Atlanta at GDPNow. The forecasts are expressed as changes in the annual rate of real (inflation-adjusted) growth in GDP. The website includes a misleading graph of the increasing accuracy of the forecasts. It is misleading because the forecasts are compared to the initial estimates of quarterly GDP changes issued by the Bureau of Economic Analysis (BEA). When the estimates are compared with BEA’s final estimates of quarterly GDP, this is the result:
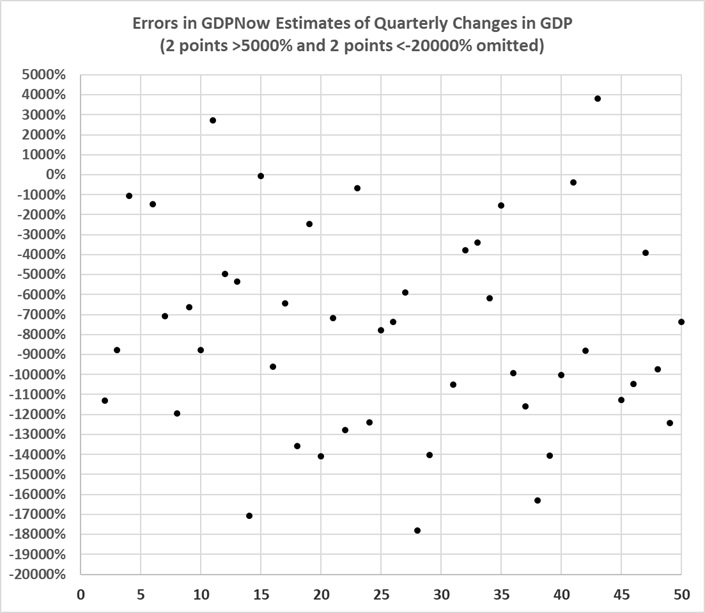
Need I say more?
Just one more thought about economics before I shift to a seemingly sacrosanct model: Einstein’s general theory of relativity. The additional thought is this: GDP is defined by simple equations, the simplest of which is GDP = C + I + G, where C is consumption expenditures, I is investment expenditures, and G is government expenditures. The equation implies that GDP rises if G rises. But that isn’t the case, as shown here.
Economics is a soft target. General relativity is a relatively (pun) hard one. But it’s not impregnable. To begin where we ought to begin, “theory” (in the physical sciences) refers to a hypothesis that has been “confirmed” by evidence (experiments, observations) and remains valid (e.g., consistently accurate in predicting the behavior of objects within its scope).
There’s a subtle catch, however. As William Briggs observes here,
Classical hypothesis testing is founded on the fallacy of the false dichotomy. The false dichotomy says of two hypotheses that if one hypothesis is false, the other must be true.
In the case of general relativity, which is really an explanation of gravity, it became obvious that Newton’s “law” of gravitation is inadequate on a large scale (e.g., it couldn’t explain the precession of Mercury’s orbit). It is considered “correct enough” on a small scale (e.g., Earth), but “incomplete”. Which is to say that it is incorrect.
General relativity solved the precession problem, among others. But is it correct, that is, complete? Apparently not. As scientists learn more and more about the universe, lacunae abound in the general theory:
The current understanding of gravity is based on Albert Einstein‘s general theory of relativity, which incorporates his theory of special relativity and deeply modifies the understanding of concepts like time and space. Although general relativity is highly regarded for its elegance and accuracy, it has limitations: the gravitational singularities inside black holes, the ad hoc postulation of dark matter, as well as dark energy and its relation to the cosmological constant are among the current unsolved mysteries regarding gravity,[3] all of which signal the collapse of the general theory of relativity at different scales and highlight the need for a gravitational theory that goes into the quantum realm. At distances close to the Planck length, like those near the center of a black hole, quantum fluctuations of spacetime are expected to play an important role.[4] Finally, the discrepancies between the predicted value for the vacuum energy and the observed values (which, depending on considerations, can be of 60 or 120 orders of magnitude)[5][6] highlight the necessity for a quantum theory of gravity.
Imagine the errors in all of the equations that are used (explicitly or implicitly) in the making of things that human beings use. What saves humanity from utter chaos — in the physical realm — is the practice of “over-building” — allowing for abnormal conditions and unknown factors in the construction of machinery, vehicles, buildings, aircraft, spacecraft, etc. Even then, the practice is often ignored or inadequate in particular situations (e.g., rocket-launch failures, bridge collapses, aircraft accidents).
The usual response to the failure of physical systems is that they are the result of “random events”. In fact, when they occur in spite of “over-building” they are the result of the inadequacy of equations to capture reality.
This brings me to so-called conspiracy theories (hypotheses, really). Some of them are patently ludicrous. Others are plausible. Most famously, perhaps, are hypotheses about who really killed JFK (or had him killed), and how he was killed. Those who scoff at such hypotheses usually do so because they don’t want them to be correct, and wish to hew to the official line. Hypotheses about the killing of JFK are plausible because of uncertainty about the “facts” that support the official view of events: Lee Harvey Oswald was the lone gunman and he acted alone.
In the case of the assassination of JFK, the following questions reflect some of the uncertainty about several (but far from all) of the official “facts”:
- Why did the Secret Service chose a route through Dallas that would bring the presidential motorcade to a halt before slowly resuming speed in front of a seven-story building?
- Who, at the highest level, approved the route?
- Why hadn’t the building been thoroughly inspected and brought under tight control, given that its location vis-a-vis the route was well known?
- How many shots were fired at JFK?
- From what position or positions were the shots fired?
- What was nature of the CIA’s involvement with Lee Harvey Oswald?
- Why did Jack Ruby — a man with “mob” connections — really kill Lee Harvey Oswald?
- Who stood to gain from JFK’s death? (Assuming Oswald as the lone gunman conveniently eliminates LBJ; the CIA, in revenge for the Bay of Pigs fiasco and JFK’s punitive reaction; RFK’s anti-mob crusade).
And so on.
The real world is full of uncertainty. But few human beings seem to be comfortable with it. Thus, crap science, science on a pedestal (of sand), and conspiracy theories.
What we wish for ourselves — decisions that have certain outcomes — isn’t aligned with the way the world works. But we keep trying, despite the odds. What else can we do?